Chisme y Python: Las conversaciones por WhatsApp con mi mejor amiga
Publicado el 27 de abril de 2020
[ENGLISH] Read here the English version of this article, but beware, plots won't render dynamically.

Hola mis cielas, el día de hoy les vengo a presentar a Teresa. Ella es mi mejor amiga desde que teníamos 12 años. Cuando éramos pequeñas, nuestras mamás tenían que desconectar el cable del teléfono fijo porque nos quedábamos hablando hasta las dos de la mañana. Hoy en día esa adicción se pasó al mundo del WhatsApp y como la buena ñ̶o̶ñ̶a̶ científica de datos que soy, aquí les traigo un análisis de nuestras conversaciones.
🤓 Los datos

Son 15.985 mensajes desde el 20 de febrero del 2019 (cuando cambié de celular) hasta el 27 de abril del 2020 (hoy).
De esos 432 días, hablamos 274 días, es decir 63% del tiempo; lo cual nos da un promedio de 58 mensajes por día.
+-----------------+---------+
| Tipo de Mensaje | Cuántos |
+-----------------+---------+
| Texto | 12.287 |
| Audio | 1.516 |
| RISA | 989 |
| Foto/Video | 809 |
| Sticker/GIF | 377 |
+-----------------+---------+
La mayoría de esos mensajes son de texto. Nótese que tuve que hacer una categoría para los mensajes que sólo contuvieran risas (ósea que ni siquiera estoy incluyendo los mensajes que tienen texto y risas), porque nos reímos y nos reímos DEMASIADO.
🤣 Risas
- La risa más popular es
Jajajajacon 128 repeticiones. - La más corta es
Jajjcon tan sólo cuatro caracteres. - La más larga es…
JAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJAJA¡Esos son 1.950 caracteres!
Naturalmente, la siguiente pregunta es ¿quién se ríe más? En promedio, la risa de Tere es de 18 caracteres, mientras que la mía es más corta con 12 caracteres en promedio; y como vemos en la visualización de abajo, la mayoría del tiempo nos reímos como las personas normales (menos de 20 caracteres) pero de vez en cuando nos reimos más de la cuenta, especialmente Tere.
👀 ¿Quién ignora a quién?
+---------+-----------------+
| Quién | No. de Mensajes |
+---------+-----------------+
| Teresa | 9.025 |
| Viviana | 6.960 |
+---------+-----------------+
En infinitas ocasiones nos hemos dicho la una a la otra: “¡Pero es que tú siempre me ignoras!”. Pues el debate finalmente se resuelve el día de hoy y el veredicto es a favor de Teresa, con más de 2.000 mensajes que yo.
+--------------+---------+-----------------+
| Tipo | Quién | No. de Mensajes |
+--------------+---------+-----------------+
| Texto | Teresa | 7.132 |
| Texto | Viviana | 5.155 |
| Audio | Teresa | 755 |
| Audio | Viviana | 741 |
| Imagen/Video | Teresa | 375 |
| Imagen/Video | Viviana | 434 |
| Sticker/GIF | Teresa | 172 |
| Sticker/GIF | Viviana | 205 |
+--------------+---------+-----------------+
Pero no me iba a dar por vencida así de fácil en este debate. Si examinámos los mensajes por categoria, nos damos cuenta que hay casi la misma cantidad de mensajes de audio, los cuales son nuestro principal medio de comunicación. Además, con la cantidad de imagenes y stickeres que envio queda claro que yo soy la reina de los memes.
📅 ¿Cuándo hablamos?
Ningún análisis estaría completo sin considerar el tiempo como una dimensión. Pero lo más interesante está si miramos el número de mensajes por día de la semana. ¿Cómo así que el lunes es el día que más hablamos? ¡Ni que fueramos la tarea del colegio!
🐸 Y lo que todos se preguntan… ¿de qué hablamos?
Llegó la hora… con el siguiente código sabremos sobre quiénes hablamos tanto, por nombres propios.
for c in Counter(text_tere_clean).most_common():
if list(pp.tag(c[0])[0])==['GivenName'] and not d.check(c[0]) and len(set(c[0])) != 2:
if not d2.check(c[0]):
print(c)
for c in Counter(text_vivi_clean).most_common():
if list(pp.tag(c[0])[0])==['GivenName'] and not d.check(c[0]) and len(set(c[0])) != 2:
if not d2.check(c[0]):
print(c)
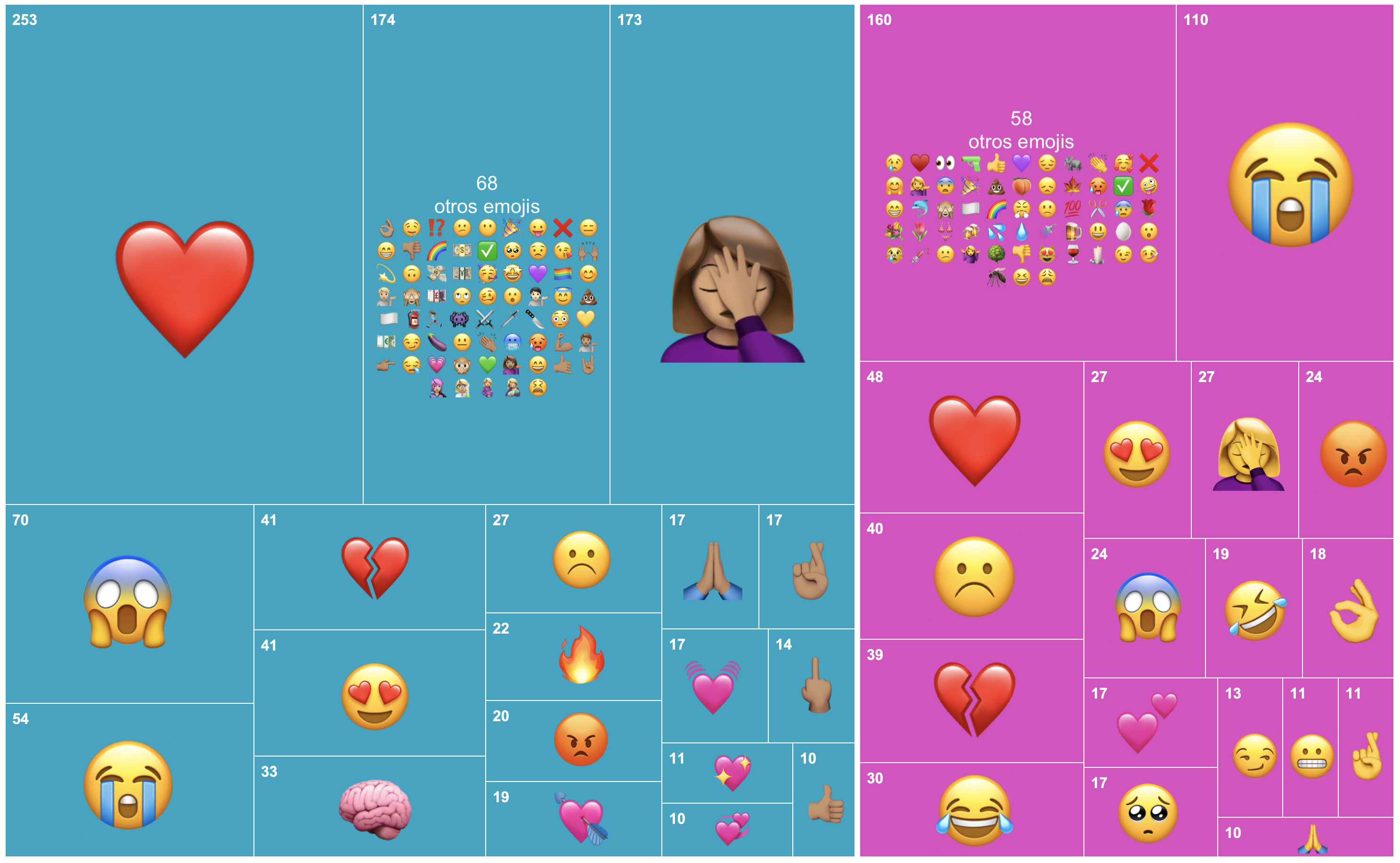
¡Já! Ya creyeron. Esos nombres no se pueden revelar sin amenazar con desintegrar la mismísima fábrica del tiempo-espacio. Mejor veamos cuáles son las palabras y los emojis más usados.
🧠 Red Neuronal Artificial
Para completar este blog, creé dos redes neuronales artificiales que imitan la manera en que nosotras hablamos. Esta es quizás la parte que más me emociona de este blog, porque apenas unos años atrás hubiera pensado que esto era un capítulo salido de Black Mirrors.
La red neuronal la entrené usando nuestras conversaciones de WhatsApp. Con poco entrenamiento, la red neuronal simplemente produce “basura”, es decir un montón de caracteres sin sentido. Así fue el progreso de la red neuronal:
-
Con poco entrenamiento:

-
Con más entrenamiento:

-
Después de varias horas de entrenamiento:

Suenan los tambores… Este es el resultado final:

Con más entrenamiento la red neuronal seguro diría cosas más coherentes, pero por ahora yo planeo empezar a usar piloma como palabra, y espero que ustedes también, mis cielas. ¡Gracias por leerme! 😘
——
¿Te gustó este artículo y quisieras hacer lo mismo con tu historial de WhatsApp? Déjamelo saber con un mensaje para hacer un video tutorial, pero por ahora puedes ver todo el código en GitHub.
Viviana Márquez
Científica de Datos en Miami, Fl.
MSc. Ciencia de Datos - Universidad de San Francisco, California
BSc. Matemáticas - Konrad Lorenz Fundación Universitaria