Redes Neuronales y Transformers¶
NLP - Analítica Estratégica de Datos¶
Fundación Universitaria Konrad Lorenz
Docente: Viviana Márquez vivianam.penama@konradlorenz.edu.co
Clase #14: Mayo 27, 2021
Fundación Universitaria Konrad Lorenz
Docente: Viviana Márquez vivianam.penama@konradlorenz.edu.co
Clase #14: Mayo 27, 2021
(El taller 9 aún está pendiente por calificar, les entrego notas la próxima clase de lo que tenemos...)

1950: Alan Turing describió una "máquina pensante". Afirmó que si una máquina pudiera participar en una conversación e imitara a un humano de forma tan completa que no hubiera diferencias perceptibles, entonces la máquina podría considerarse capaz de pensar.
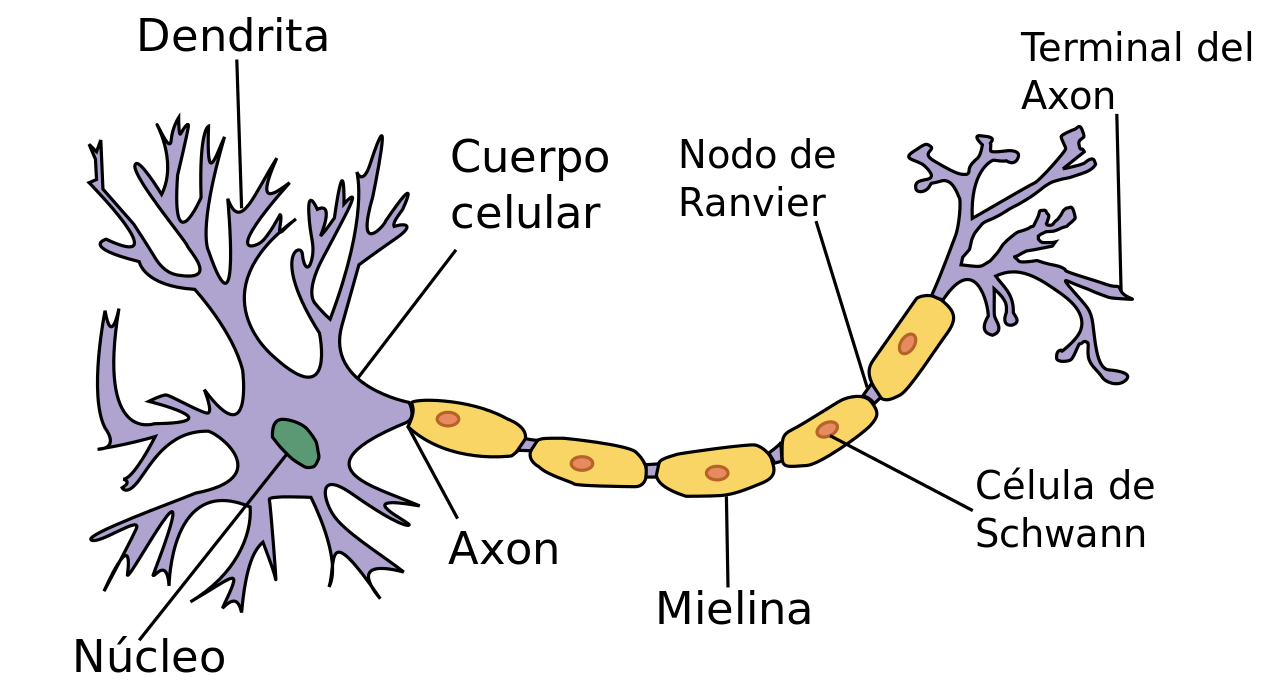
1952: El modelo Hodgkin-Huxley mostró cómo el cerebro utiliza las neuronas para formar una red eléctrica.
^ Eso inspiró la creación de AI & NLP & la evolución de los computadores.
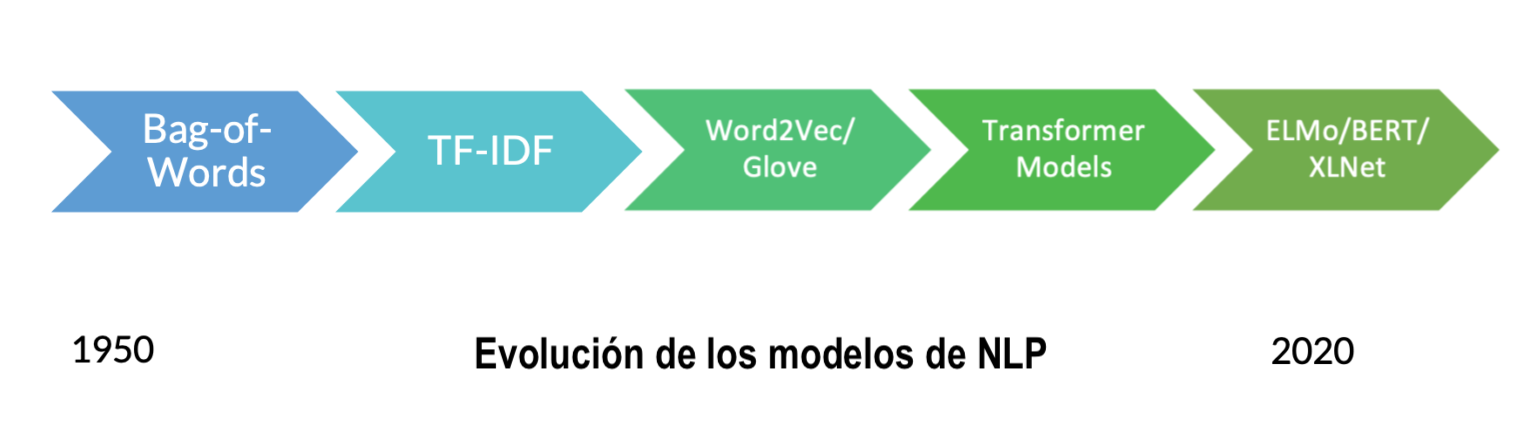
1954: Bag of Words
2013: Word2Vec
2018: Transformers
Recordemos que NLP tiene muchas aplicaciones en la vida real que usan diferentes técnicas.
YouTube: https://www.youtube.com/watch?v=cQ54GDm1eL0&ab_channel=BuzzFeedVideo
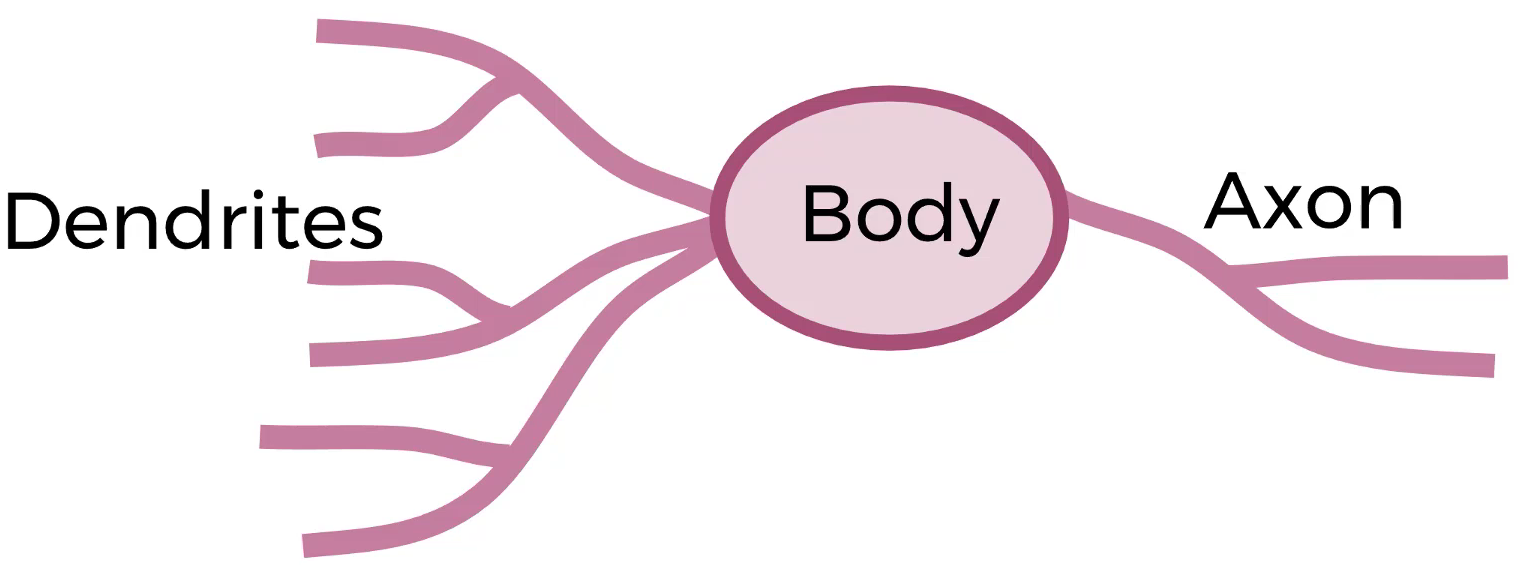
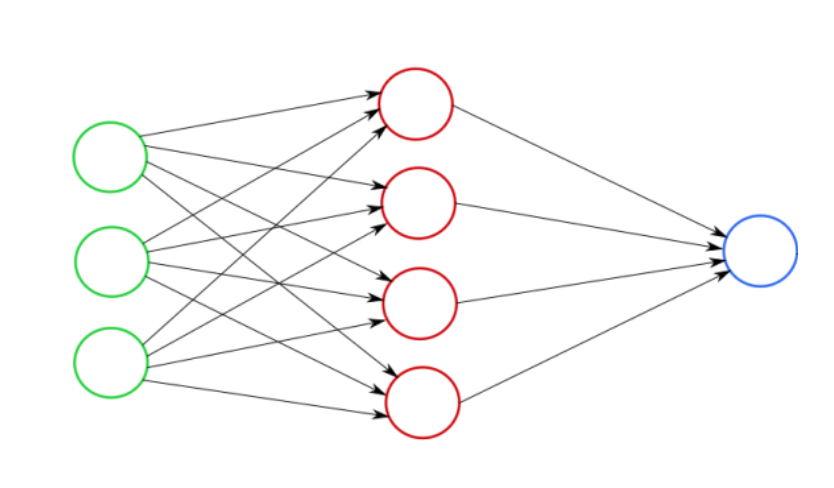
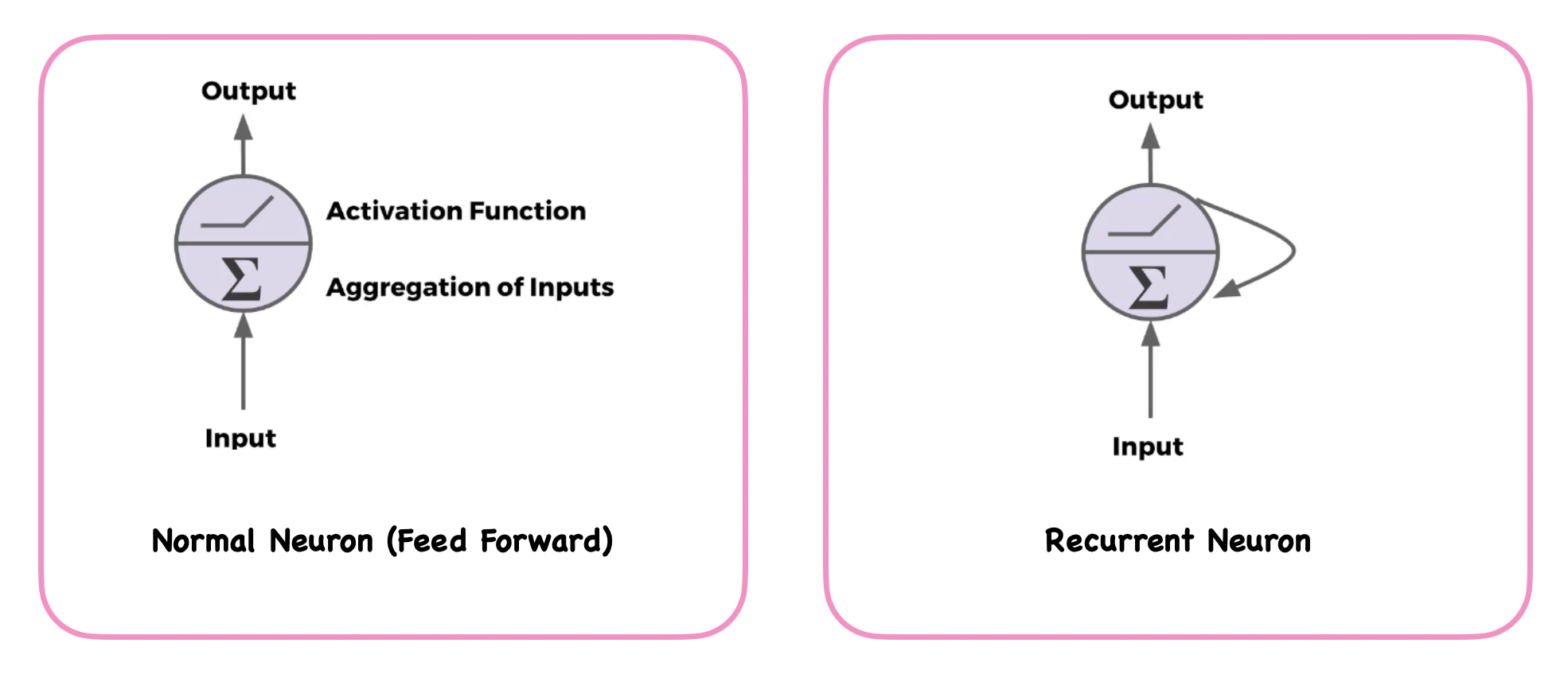
De una manera simplificada:
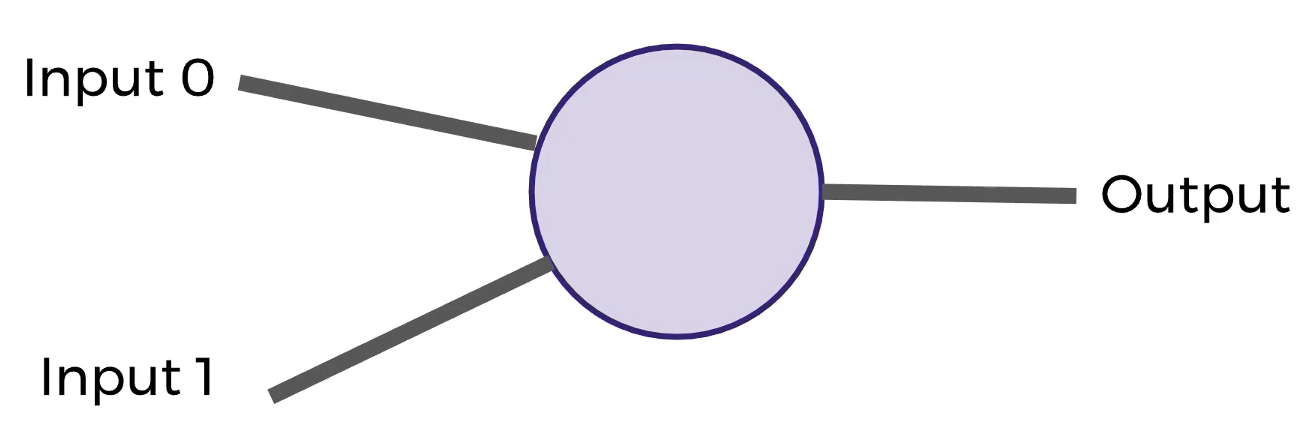
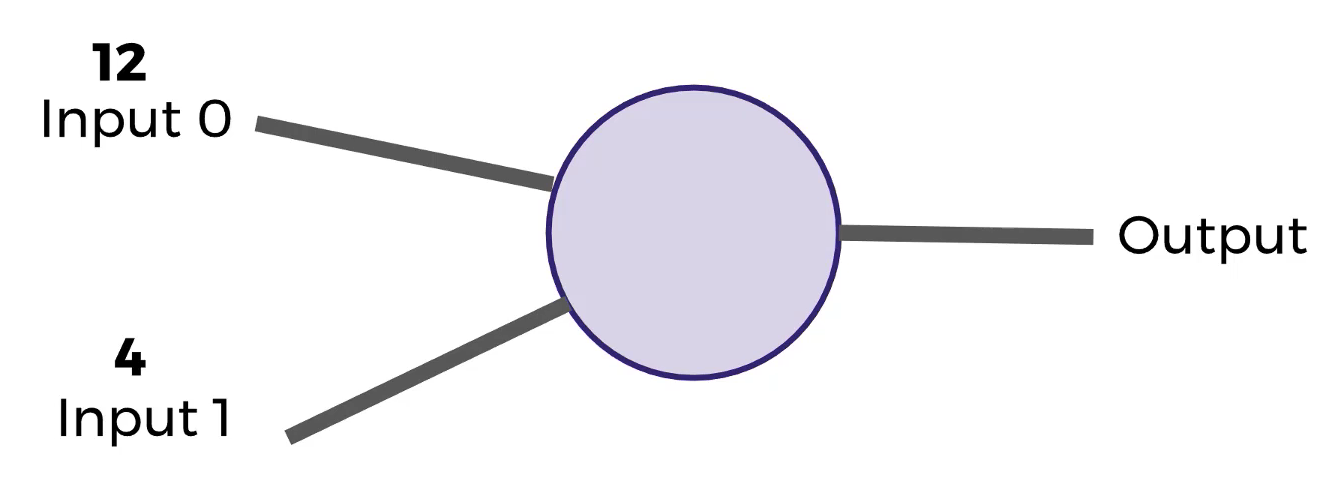
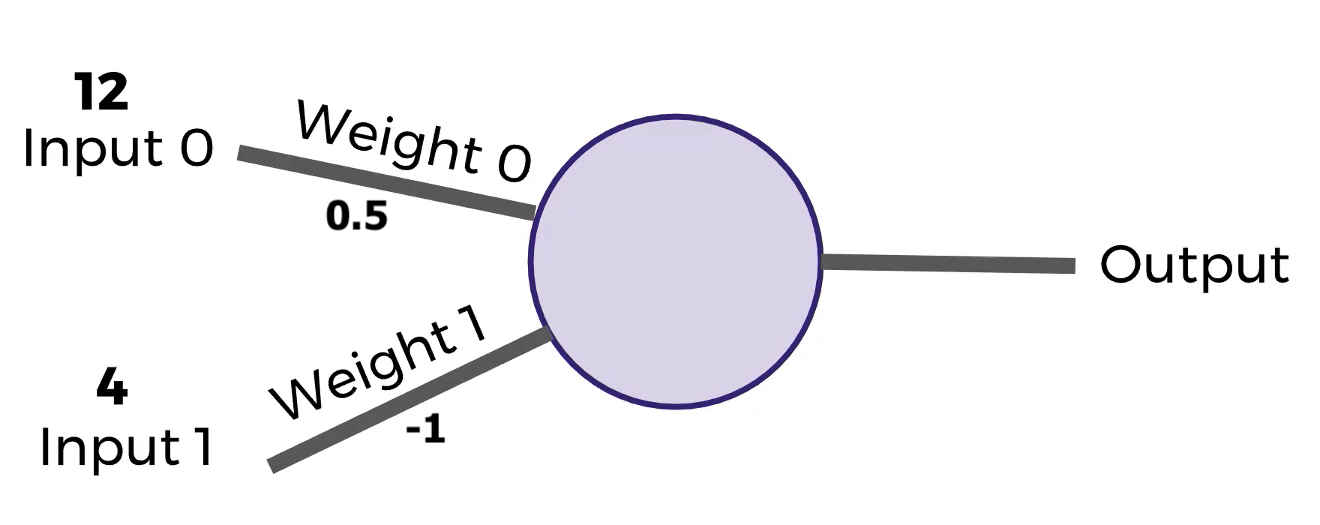
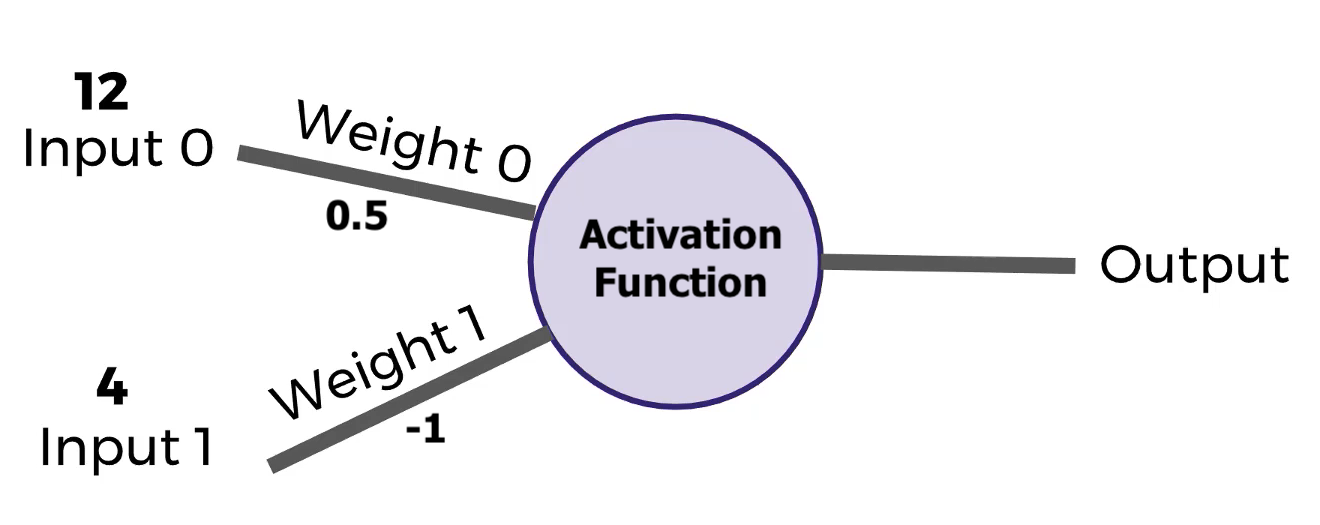

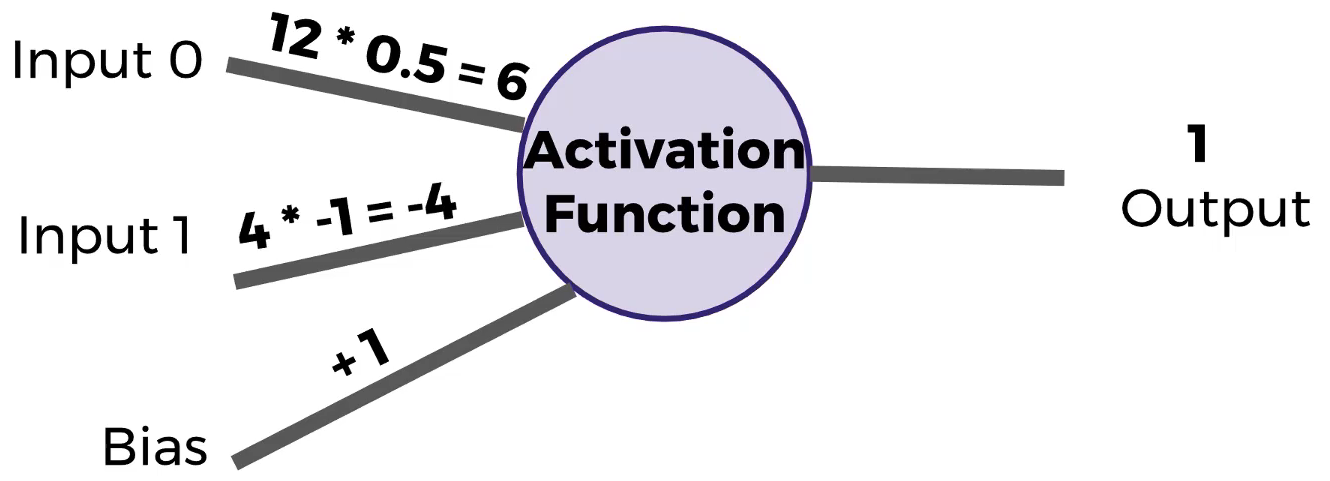
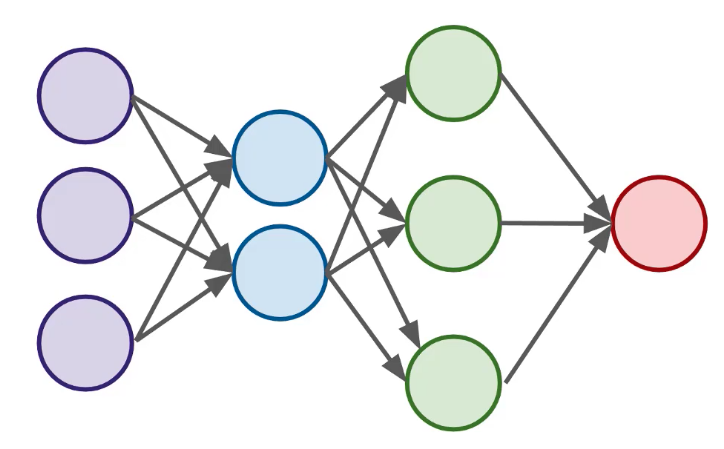
Partes:
A medida que crece el número de capas, crece el nivel de abstracción
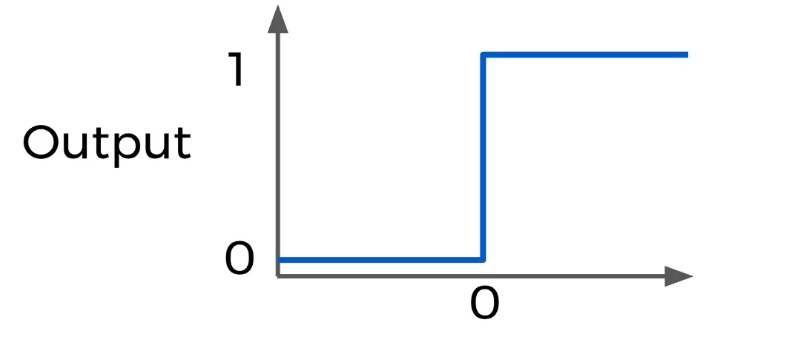
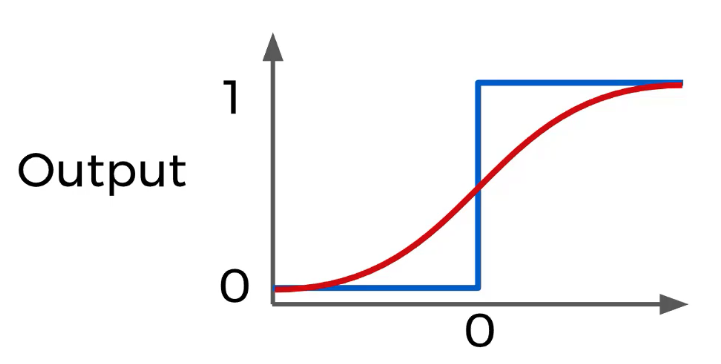
Hugging Face es una startup que ofrece 30 modulos pre-entrenados en más de 100 idiomas y 8 arquitecturas para NLU & NLG.
# pip install transformers
from transformers import pipeline, set_seed
generator = pipeline('text-generation', model='gpt2')
resultado = generator("Hi, how are you?", max_length=60, num_return_sequences=7)
Some weights of GPT2Model were not initialized from the model checkpoint at gpt2 and are newly initialized: ['h.0.attn.masked_bias', 'h.1.attn.masked_bias', 'h.2.attn.masked_bias', 'h.3.attn.masked_bias', 'h.4.attn.masked_bias', 'h.5.attn.masked_bias', 'h.6.attn.masked_bias', 'h.7.attn.masked_bias', 'h.8.attn.masked_bias', 'h.9.attn.masked_bias', 'h.10.attn.masked_bias', 'h.11.attn.masked_bias'] You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference. Setting `pad_token_id` to `eos_token_id`:50256 for open-end generation.
for r in resultado:
print(r['generated_text'])
print("*"*100)
Hi, how are you? And how do you keep the whole system going in just a few days? Thanks so much! Please let us know what you think. Please, please, give us more info about it.. If you want, please email us. Till **************************************************************************************************** Hi, how are you? Your response on the second page of the blog? Are you still an employee? Yes! I've been a bit of a 'wonderboy' here but just about everybody in the company has worked for me lately and I appreciate that. **************************************************************************************************** Hi, how are you? The only way is if she'll come out at this point. Right. Q: Now that we have the best candidate to get this thing going, so what's next? I thought I could tell you a quick summary of that, and then we **************************************************************************************************** Hi, how are you? How do you deal with the problem of a bunch of people on this planet that come together, come to live their lives all to themselves, be true to their values. AMY GOODMAN: Talk a little bit about the history of immigration, what's different recently, **************************************************************************************************** Hi, how are you? It's very bad, but it's also very good as a good news story. I'm going to tell you an even better story next. I'm about to get out of the hospital and you're here. Have you heard what people have been **************************************************************************************************** Hi, how are you? I hope you don't mind. It just won't give me any headaches this summer. I mean, it's all just not happening. So, you've got to be really patient with this, okay?" "Yes." Harry answered, and then nodded. **************************************************************************************************** Hi, how are you? Are you feeling well, my dear? What kind of person are you? You see, the other people in the world have these strange beliefs? And they are always in pain, always. They believe all sorts of nonsense. No, they're very intelligent, they know ****************************************************************************************************
classifier = pipeline('sentiment-analysis')
classifier('I am so happy with my students')
[{'label': 'POSITIVE', 'score': 0.9998819828033447}]
question_answerer = pipeline('question-answering')
question_answerer({
'question': 'What is the capital of Colombia?',
'context': 'Bogotá is the capital of Colombia'})
/opt/anaconda3/lib/python3.7/site-packages/transformers/tokenization_utils_base.py:1423: FutureWarning: The `max_len` attribute has been deprecated and will be removed in a future version, use `model_max_length` instead. FutureWarning,
{'score': 0.9964471459388733, 'start': 0, 'end': 6, 'answer': 'Bogotá'}
unmasker = pipeline('fill-mask', model='bert-base-cased')
unmasker("Hello, my name is [MASK].")
Some weights of the model checkpoint at bert-base-cased were not used when initializing BertForMaskedLM: ['cls.seq_relationship.weight', 'cls.seq_relationship.bias'] - This IS expected if you are initializing BertForMaskedLM from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model). - This IS NOT expected if you are initializing BertForMaskedLM from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
[{'sequence': '[CLS] Hello, my name is David. [SEP]',
'score': 0.007386402226984501,
'token': 1681,
'token_str': 'David'},
{'sequence': '[CLS] Hello, my name is James. [SEP]',
'score': 0.006773959379643202,
'token': 1600,
'token_str': 'James'},
{'sequence': '[CLS] Hello, my name is Sam. [SEP]',
'score': 0.006729594897478819,
'token': 2687,
'token_str': 'Sam'},
{'sequence': '[CLS] Hello, my name is Charlie. [SEP]',
'score': 0.0059125544503331184,
'token': 4117,
'token_str': 'Charlie'},
{'sequence': '[CLS] Hello, my name is Kate. [SEP]',
'score': 0.0057940054684877396,
'token': 5036,
'token_str': 'Kate'}]
from transformers import pipeline, set_seed
summarizer = pipeline("summarization")
ARTICLE = """The Apollo program, also known as Project Apollo, was the third United States human spaceflight program carried out by the National Aeronautics and Space Administration (NASA), which accomplished landing the first humans on the Moon from 1969 to 1972.
First conceived during Dwight D. Eisenhower's administration as a three-man spacecraft to follow the one-man Project Mercury which put the first Americans in space,
Apollo was later dedicated to President John F. Kennedy's national goal of "landing a man on the Moon and returning him safely to the Earth" by the end of the 1960s, which he proposed in a May 25, 1961, address to Congress.
Project Mercury was followed by the two-man Project Gemini (1962-66).
The first manned flight of Apollo was in 1968.
Apollo ran from 1961 to 1972, and was supported by the two-man Gemini program which ran concurrently with it from 1962 to 1966.
Gemini missions developed some of the space travel techniques that were necessary for the success of the Apollo missions.
Apollo used Saturn family rockets as launch vehicles.
Apollo/Saturn vehicles were also used for an Apollo Applications Program, which consisted of Skylab, a space station that supported three manned missions in 1973-74, and the Apollo-Soyuz Test Project, a joint Earth orbit mission with the Soviet Union in 1975.
"""
summary=summarizer(ARTICLE, max_length=100, min_length=30, do_sample=False)[0]
print(summary['summary_text'])
The Apollo program, also known as Project Apollo, was the third U.S. human spaceflight program . The first manned flight of Apollo was in 1968 . It was followed by the two-man Project Gemini (1962-66) which ran concurrently with it .
from transformers import pipeline, set_seed
nlp_token_class = pipeline('ner')
nlp_token_class('Ronaldo was born in 1985, he plays for Juventus and Portugal.')
[{'word': 'Ronald',
'score': 0.9978647828102112,
'entity': 'I-PER',
'index': 1},
{'word': '##o', 'score': 0.99903804063797, 'entity': 'I-PER', 'index': 2},
{'word': 'Juventus',
'score': 0.9977495670318604,
'entity': 'I-ORG',
'index': 11},
{'word': 'Portugal',
'score': 0.9991246461868286,
'entity': 'I-LOC',
'index': 13}]