Adquisición de Textos¶
NLP - Analítica Estratégica de Datos¶
Fundación Universitaria Konrad Lorenz
Docente: Viviana Márquez vivianam.penama@konradlorenz.edu.co
Clase #2: Febrero 25, 2020
⌛ En la clase anterior¶
• Nos presentamos 🤗
• Introducción a NLP
• Python, GitHub, cuenta de desarrollador de Twitter
git push origin main (Cambió a raíz del movimiento de BLM, gracias Brayam por el dato!)
🚀 Hoy veremos...¶
• Repaso de Python
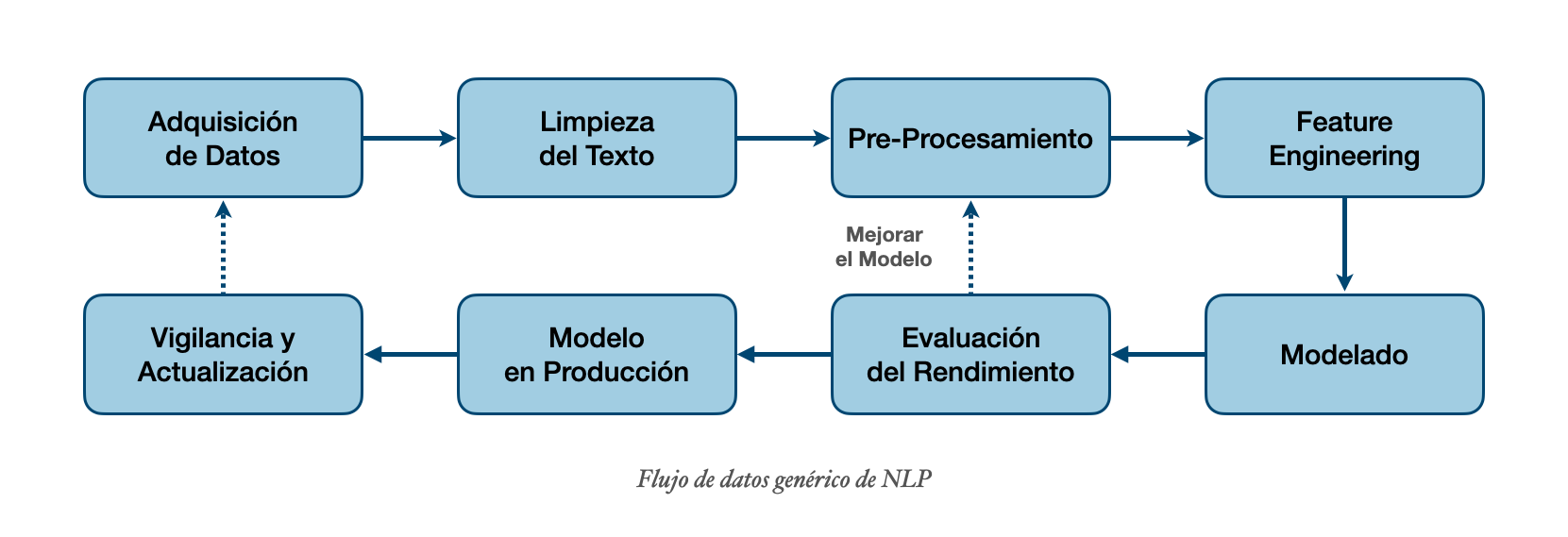
• Flujo de datos en un proyecto de NLP (pipeline)
• Métodos de adquisición de texto más comunes
• Taller #2
🐍 Python¶
Si en su empresa les piden desarrollar un proyecto, ¿cómo lo harían?
Normalmente, revisaríamos los requerimientos y dividiríamos el problema en diferentes pasos; para luego crear una estrategía para resolver cada paso.
Esto mismo se hace con los proyectos de machine learning y se le conoce como pipeline o flujo de datos. Aunque los detalles específicos varian de proyecto a proyecto, estos pasos son comunes y nos van a permitir comenzar cualquier proyecto de machine learning.
👷🏽♀️ Adquisición de datos¶
¿Cuáles son los tipos de archivos de texto más comunes?
- Datos abiertos
- txt, csv, json, zip
- Excel, Word
- (HTML) Web Scraping
- PDFs e imágenes
- Aumento de datos👷🏽♀️ Adquisición de datos: Un caso ideal¶

• Tenemos que identificar si es una consulta de servicio al cliente vs una consulta de venta
• Para esta tarea, nuestra empresa tiene miles (incluso millones) de datos
• Adicionalmente, cada uno de los datos están etiquetados
• Sin embargo, la mayoría de proyectos no tienen tanta suerte 🙁
👷🏽♀️ 1. Usar un conjunto de datos abiertos¶
- GitHub
- Kaggle: https://www.kaggle.com/
- Búsqueda de datos de Google: https://datasetsearch.research.google.com/
- Datos Abiertos Colombia: https://www.datos.gov.co/
- Datos Abiertos Bogotá: https://datosabiertos.bogota.gov.co/about
- Ministerio de Salud: https://www.minsalud.gov.co/Paginas/datos-abiertos.aspx
import pandas as pd
df = pd.read_csv("../archivos/iris.csv", sep=',')
df.head(5)
pd.read_csv?
df.species.str.cat(sep=" **** ")
with open("../archivos/grabacion.txt", encoding='utf-8') as archivo:
data = archivo.read()
print(data)
import json
with open ("../archivos/sistemas_operativos.json") as archivo:
data = json.load(archivo)
data[-1]
from pandas import json_normalize
json_normalize(data)
import os
from zipfile import ZipFile
direccion = '../archivos/astrok.zip'
# Descomprimir el archivo ZIP
with ZipFile(direccion) as archivo:
archivo.extractall("../archivos/")
import shutil
shutil.rmtree('../archivos/__MACOSX')
Para ver el nombre de los archivos:
for archivo in os.walk("../archivos/astrok"):
print(archivo)
for raiz, dirs, archivos in os.walk("../archivos/astrok"):
# print(raiz, dirs, archivos)
for a in archivos:
print(a)
Instalar libreria: pip install python-docx
import docx
documento = docx.Document("../archivos/Colombia.docx")
[print(p.text) for p in documento.paragraphs]
Para poder leer tablas dentro del archivo
tabla = documento.tables[0]
tabla
data = []
for i, fila in enumerate(tabla.rows):
f = [celda.text for celda in fila.cells]
data.append(f)
df = pd.DataFrame(data)
df.columns = df.loc[0].values
df
import pandas as pd
data = pd.read_excel("../archivos/hoja.xlsx")
data.head()
¿Y la segunda hoja?
data2 = pd.read_excel("../archivos/hoja.xlsx", sheet_name=1)
data2
url = "https://docs.google.com/spreadsheets/d/1O8k9ZBaHSPbw_8IgE-jxmVE8FkMWimr6dZPuKhAT2hM/edit#gid=0"
new_url = url.rsplit("/",1)[0] + "/gviz/tq?tqx=out:csv"
new_url
data = pd.read_csv(new_url)
data
👷🏽♀️ 5. Archivos PDF¶
Instalar libreria: pip install PyMuPDF
Créditos: Angela Cristina Villate Moreno, ejemplo
import fitz
documento = fitz.open('../archivos/cien.pdf')
print("Número de páginas: ", documento.pageCount)
print("Metados: ", documento.metadata)
pagina = documento.loadPage(0)
texto = pagina.getText("text")
print(texto)
👷🏽♀️ 5. Archivos de imagen¶
Instalar:
pip install pytesseract- Tesser OCR
- Mac:
brew install tesseract - Linux:
sudo apt-get install tesseract-ocr - Windows: https://github.com/UB-Mannheim/tesseract/wiki
- Mac:
import pytesseract
from pytesseract import image_to_string
from PIL import Image
Image.open("demo.png")
# pytesseract.pytesseract.tesseract_cmd = "C:\\Program Files\\Tesseract-OCR\\tesseract.exe"
texto = image_to_string(Image.open("demo.png"))
print(texto)
👷🏽♀️ 6. Aumentación de datos¶

• Estrategia utilizada frecuentemente en machine learning cuando no se tienen suficiente datos.
👷🏽♀️ 6. Aumentación de datos¶

• Estrategia utilizada frecuentemente en machine learning cuando no se tienen suficiente datos.
👷🏽♀️ 6. Aumentación de datos¶

• Estrategia utilizada frecuentemente en machine learning cuando no se tienen suficiente datos.
👷🏽♀️ 6. Aumentación de datos¶

• Estrategia utilizada frecuentemente en machine learning cuando no se tienen suficiente datos.

- Reemplazo de sinónimos
- Traducción de ida y vuelta
- Reemplazar entidades
- Agregar "ruido" al texto
Libreria nlpaug: https://github.com/makcedward/nlpaug
Más info: Libreria de nlpaug: https://github.com/makcedward/nlpaug
🤓 Recapitulando: Hoy aprendímos...¶
- Los diferentes pasos en un proyecto de machine learning/NLP (flujo de datos/pipeline)
- Métodos de adquisición de texto más comunes
- Usar un conjunto de datos abiertos
- Archivos más comunes:
.csv,.txt,.json,.zip - Archivos Office: Word, Excel, Google Sheets
- PDFs e imágenes
- Aumentación de datos
¡Tiempo de taller!¶

Taller # 2: Adquisición de datos de NLP.
Fecha de entrega: Marzo 4, 2020. (Antes del inicio de la próxima clase)