¿Correo basura o no?¶
Clasificación de Textos (Parte 1)¶
NLP - Analítica Estratégica de Datos¶
Fundación Universitaria Konrad Lorenz
Docente: Viviana Márquez vivianam.penama@konradlorenz.edu.co
Clase #7: Abril 8, 2021
Fundación Universitaria Konrad Lorenz
Docente: Viviana Márquez vivianam.penama@konradlorenz.edu.co
Clase #7: Abril 8, 2021
Primero hagamos un repaso de ML

• El Machine Learning (aprendizaje automático) se encarga de representar la estructura y generalizar el comportamiento de un conjunto de datos a través de un modelo.
💡 Representar: Extraer la estructura de un conjunto de datos.
💡 Generalizar: Hacer predicciones a partir de un conjunto de datos.
 Sí, pero modelos matemáticos.
Sí, pero modelos matemáticos.Estos se usan para describir un sistema (natural, físico, social, industrial, etc.) usando conceptos y lenguaje matemático.
import pandas as pd
data = pd.read_csv("../archivos/basura.csv")
data.sample(3)
| mensaje | etiqueta | |
|---|---|---|
| 517 | Envíale un mensaje de texto. Si no responde, a... | legítimo |
| 106 | Su ID de usuario único es 1172. Para eliminarl... | basura |
| 41 | Gana el más nuevo “Harry Potter y la Orden del... | basura |
 ¿Es un perro o es un muffin?
¿Es un perro o es un muffin?Dos preguntas:
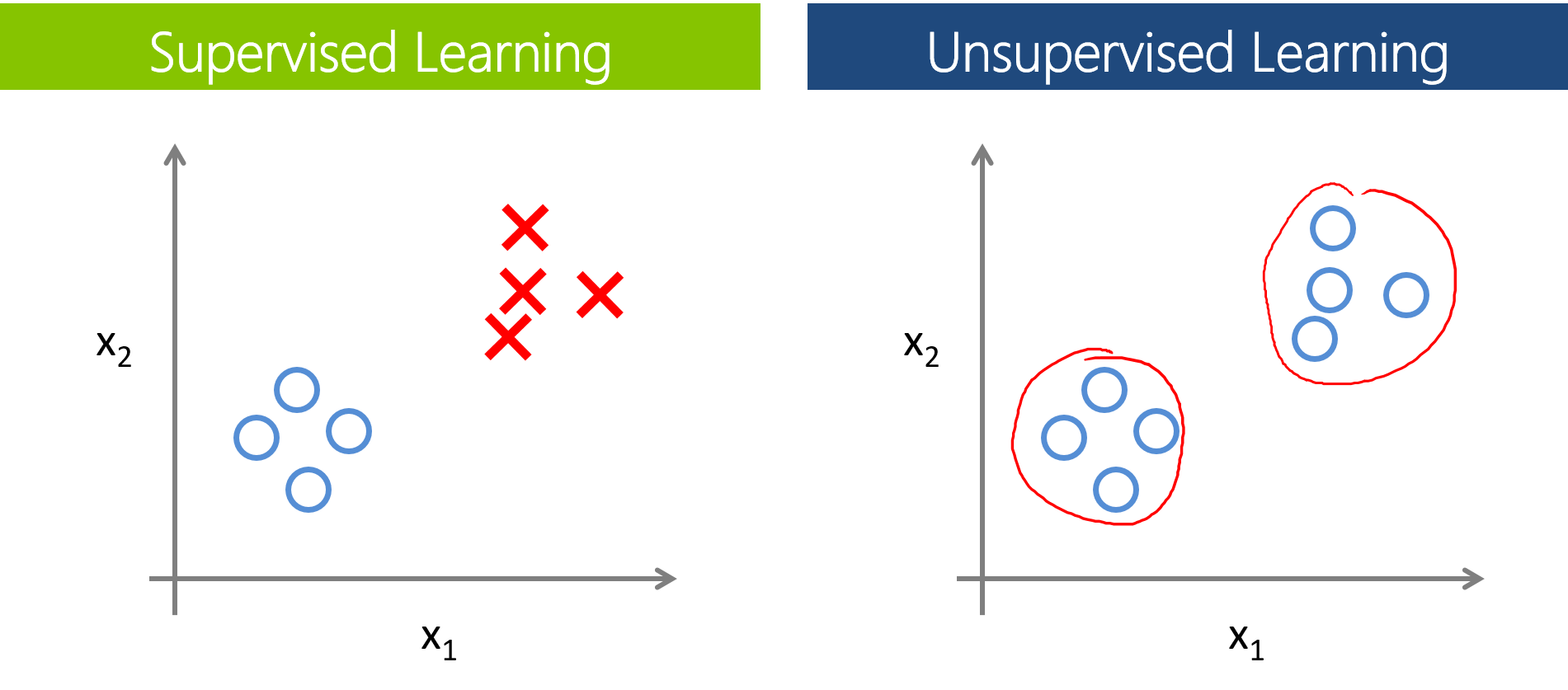
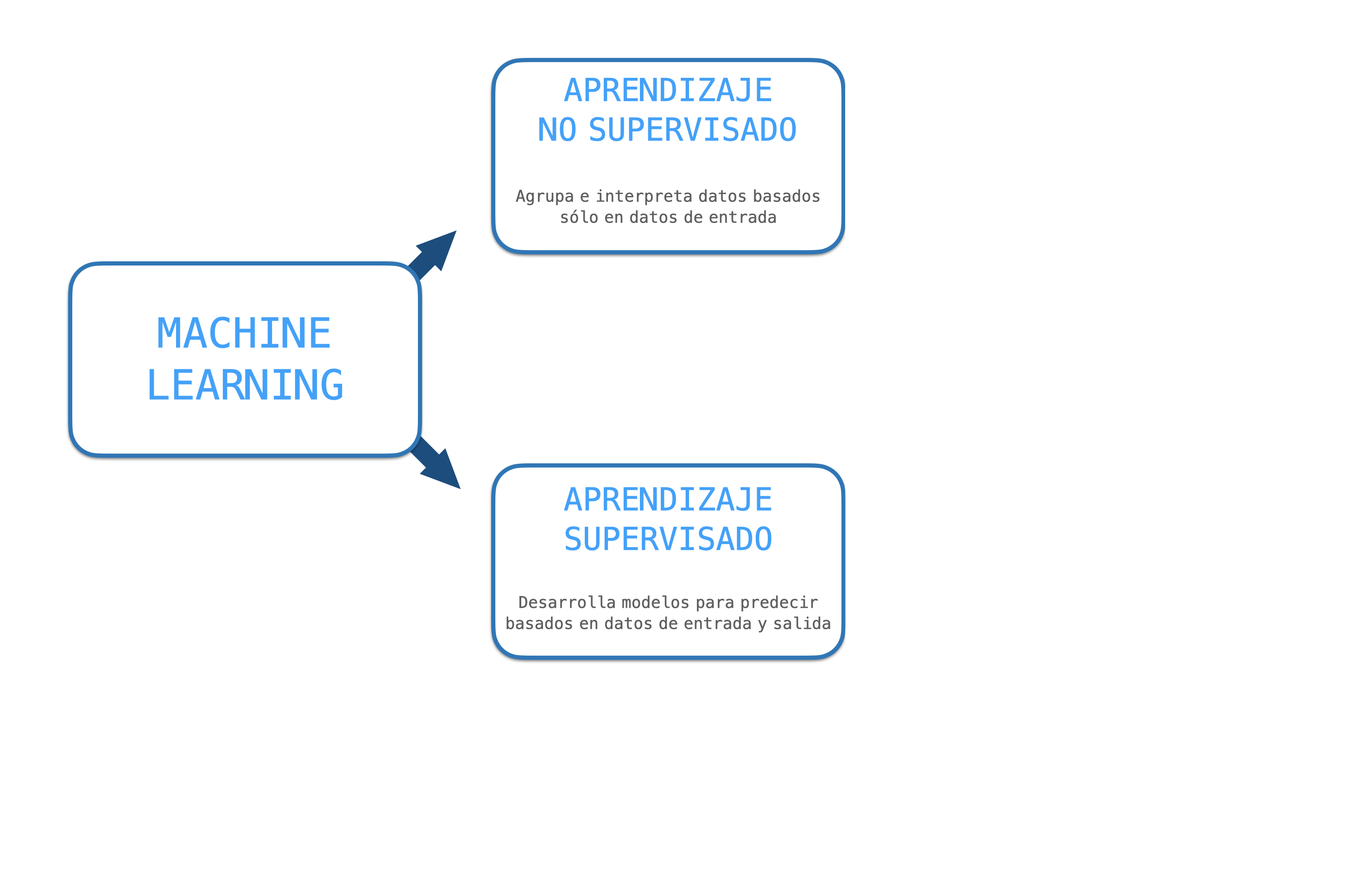
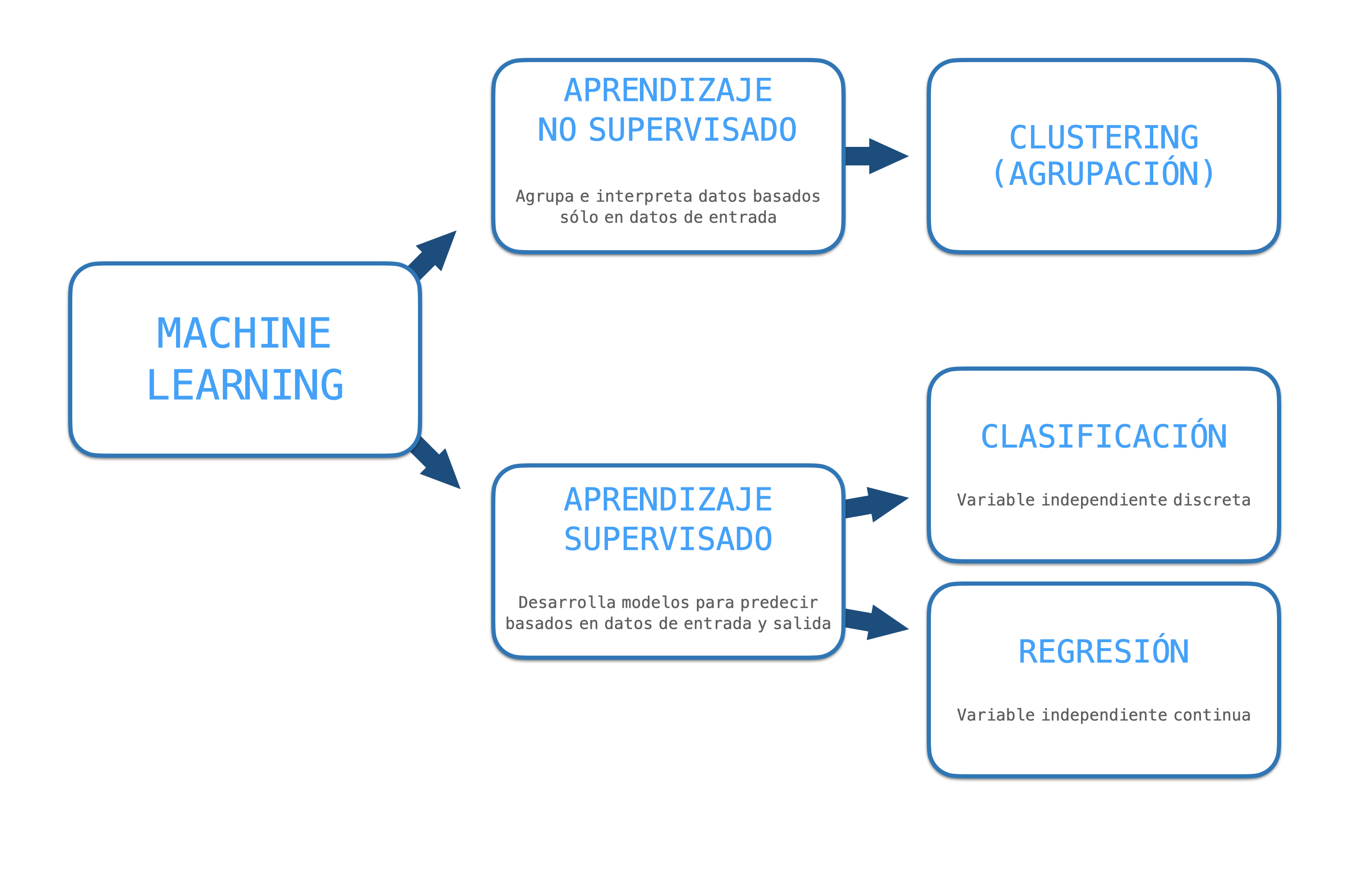
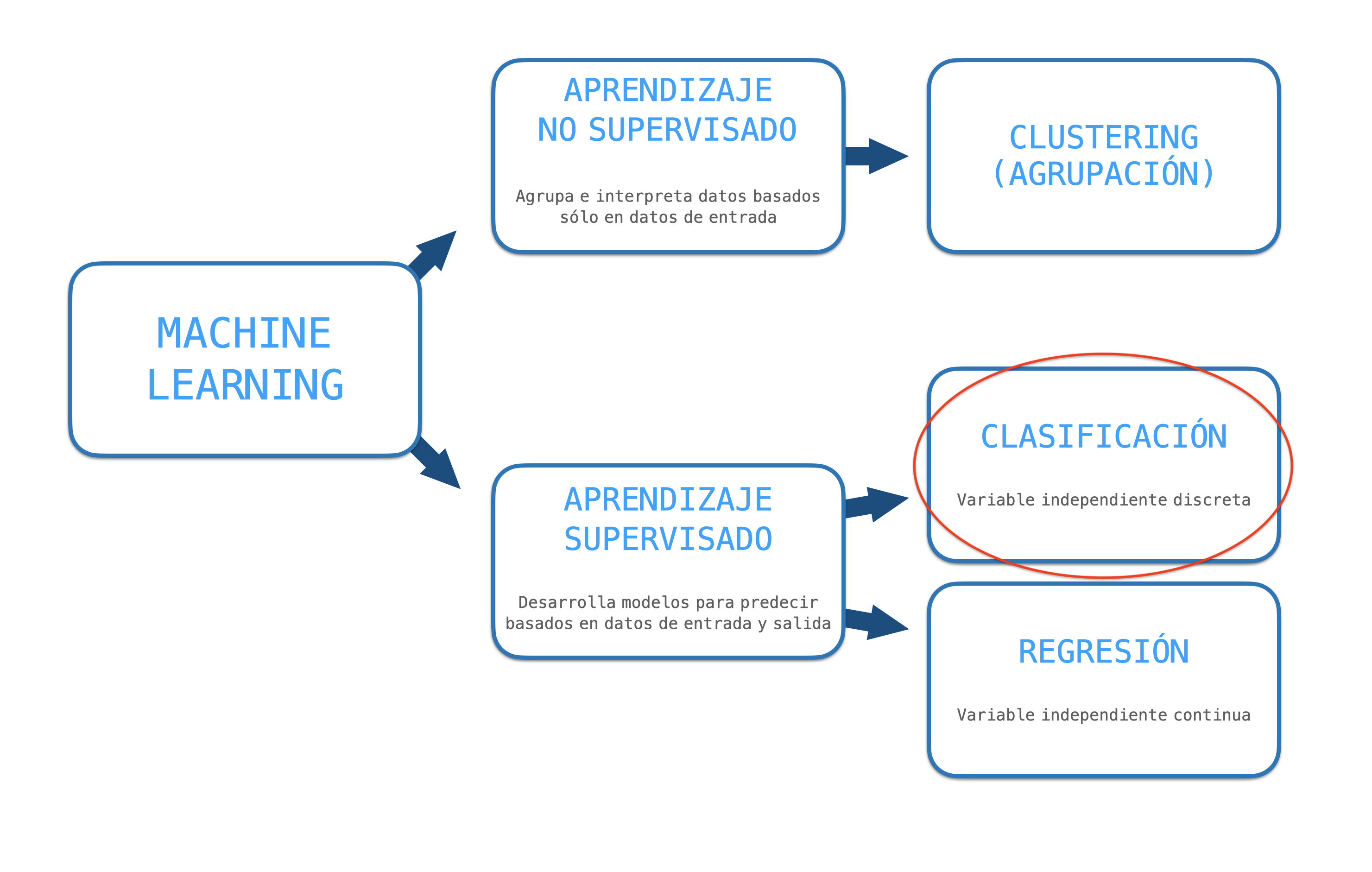
Aprendizaje supervisado: Le das a la computadora algunos pares de entradas/salidas, así en el futuro nuevo cuando se presenten nuevas entradas tienes una salida inteligente.
Aprendizaje no supervisado: Dejas que la computadora aprenda de los datos en sí sin mostrar cuál es la salida esperada.
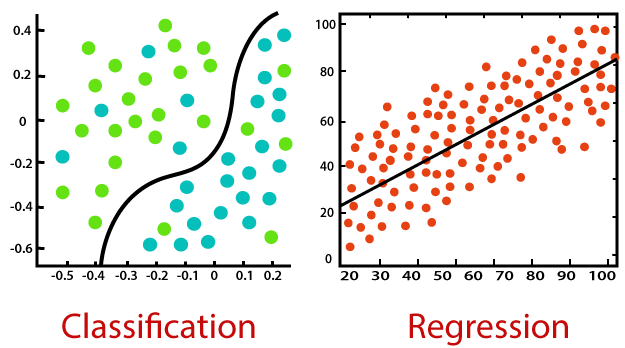
Multietiqueta: Cuando un documento puede tener más de una clase/etiqueta

¿En qué otros escenarios podemos tener un problema de multietiqueta?
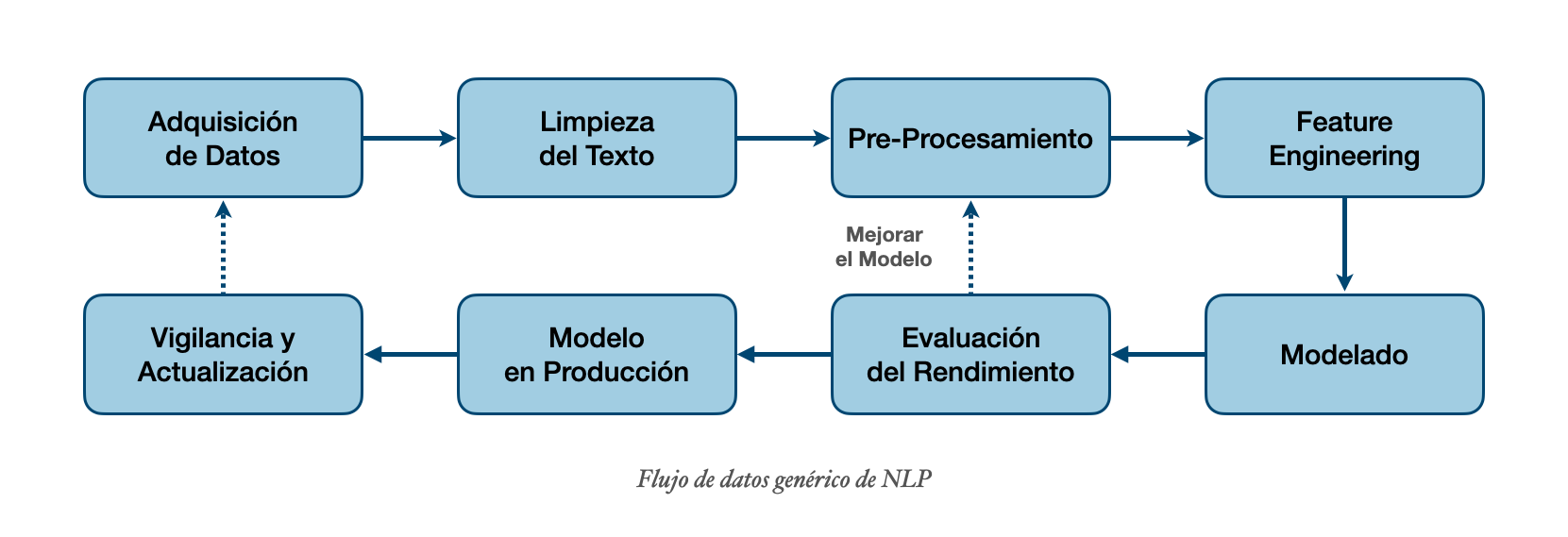
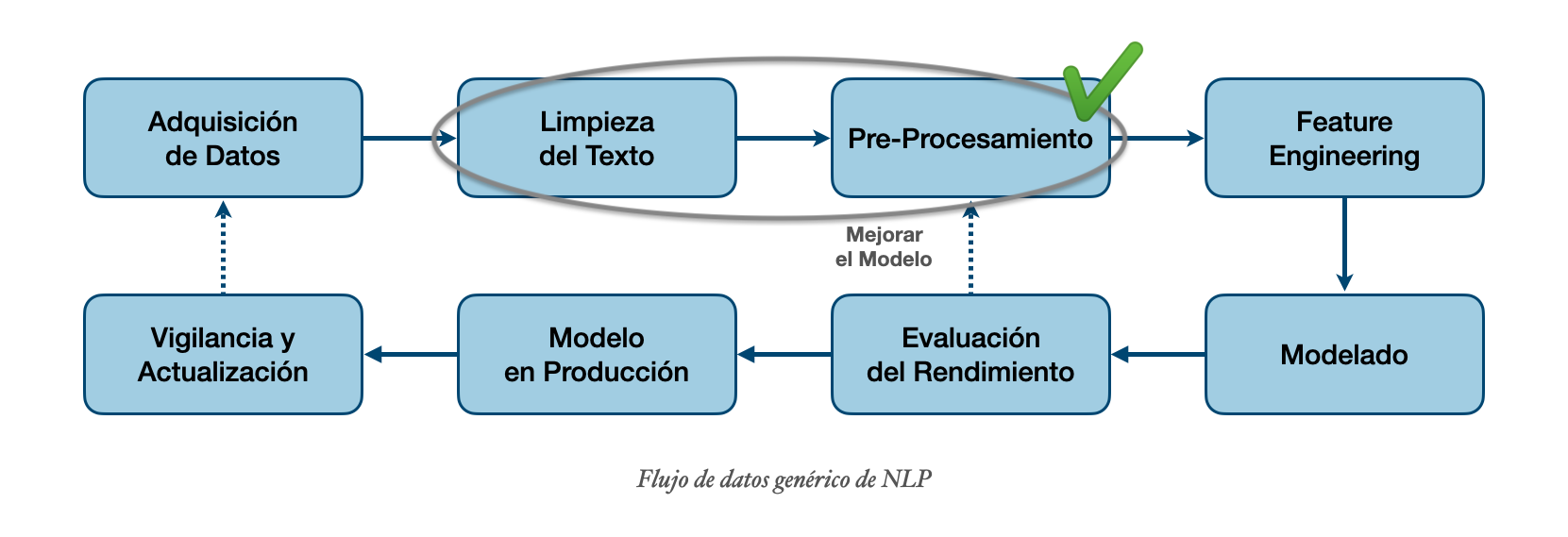
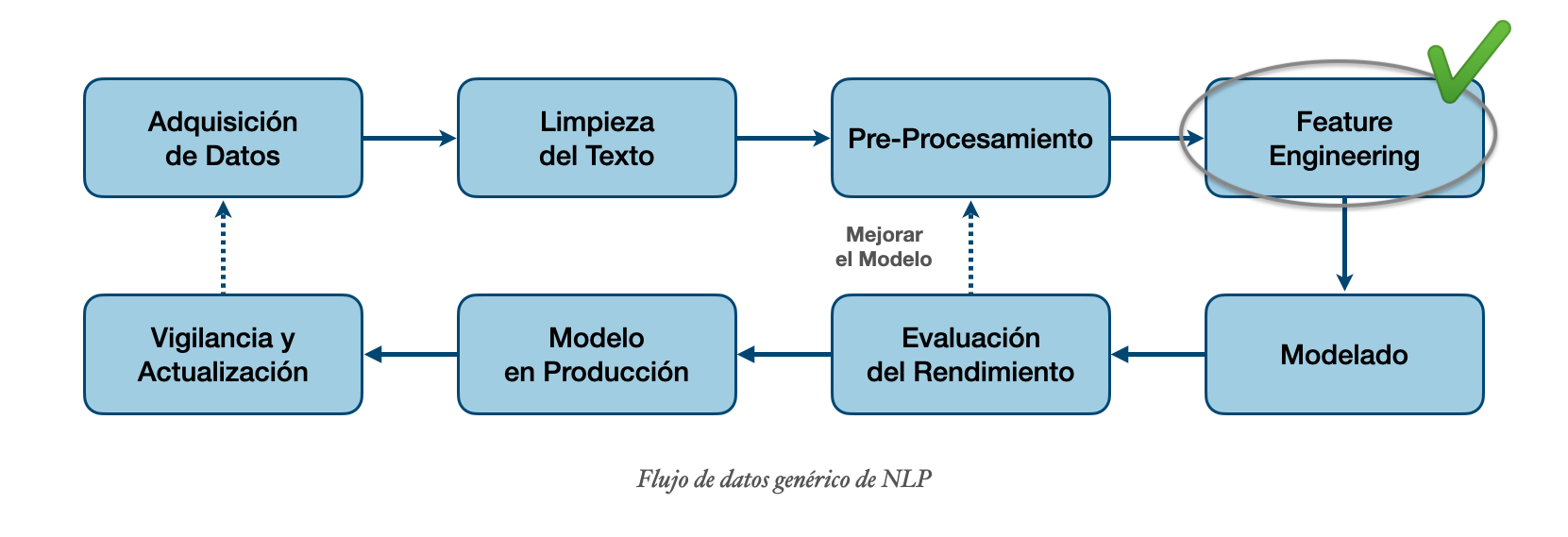
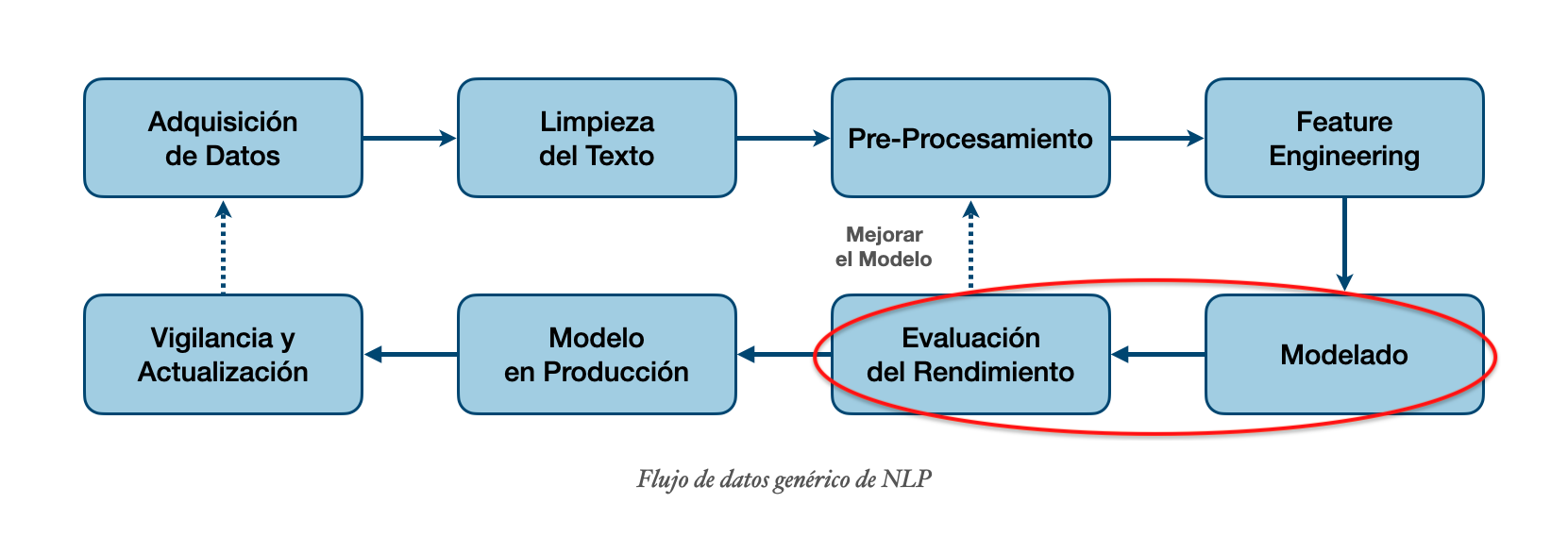
Pasos para un modelo de clasificación:
print(f"El conjunto de datos tiene {data.shape[0]} registros.")
data.sample(2)
data.etiqueta.value_counts(normalize=True)
El conjunto de datos tiene 729 registros.
basura 0.550069 legítimo 0.449931 Name: etiqueta, dtype: float64
Pasos para un modelo de clasificación:
Pasos para un modelo de clasificación:
training) y prueba (test)from sklearn.model_selection import train_test_split
train, test = train_test_split(data, test_size=0.2)
print(f"El conjunto de datos de entrenamiento tiene {train.shape[0]} registros y el de prueba tiene {test.shape[0]} registros.")
El conjunto de datos de entrenamiento tiene 583 registros y el de prueba tiene 146 registros.
Pasos para un modelo de clasificación:
training) y prueba (test)Pasos para un modelo de clasificación:
training) y prueba (test)Pasos para un modelo de clasificación:
training) y prueba (test)Algunas de las medidas más populares son:
En tu modelo puedes lograr dos resultados:
Exactitud (accuracy): El número de predicciones correctas hechas por el modelo divididas por el número total de predicciones.

Problemas con la exactitud (accuracy). Necesita un conjunto de datos balanceados.
Sensibilidad (recall): La capacidad que tiene el modelo para encontrar todos los casos relevantes dentro de un conjunto de datos.
Precisión (precision): La capacidad que tiene el modelo para encontrar sólo los casos relevantes dentro de un conjunto de datos.
Valor-F1: Sirve para encontrar un balance óptimo entre precisión y sensibilidad.
En tu modelo puedes lograr dos resultados:
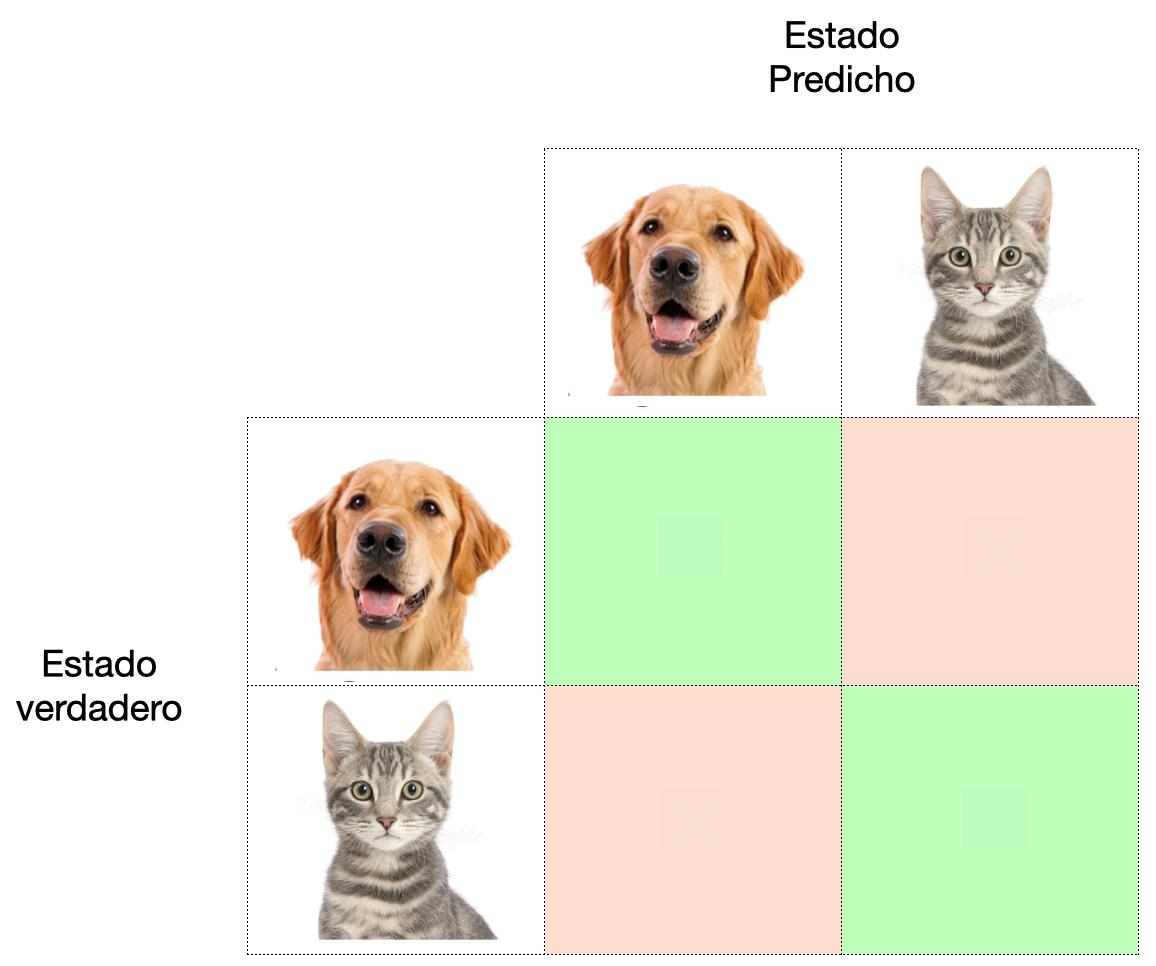
Esto quiere decir que al final tienes cuatro grupos:
clase 1: Verdadero perro

clase 2: Verdadero gato

clase 2: Falso perro

clase 1: Falso gato

Herramienta que permite la visualización del desempeño de un modelo de clasificación
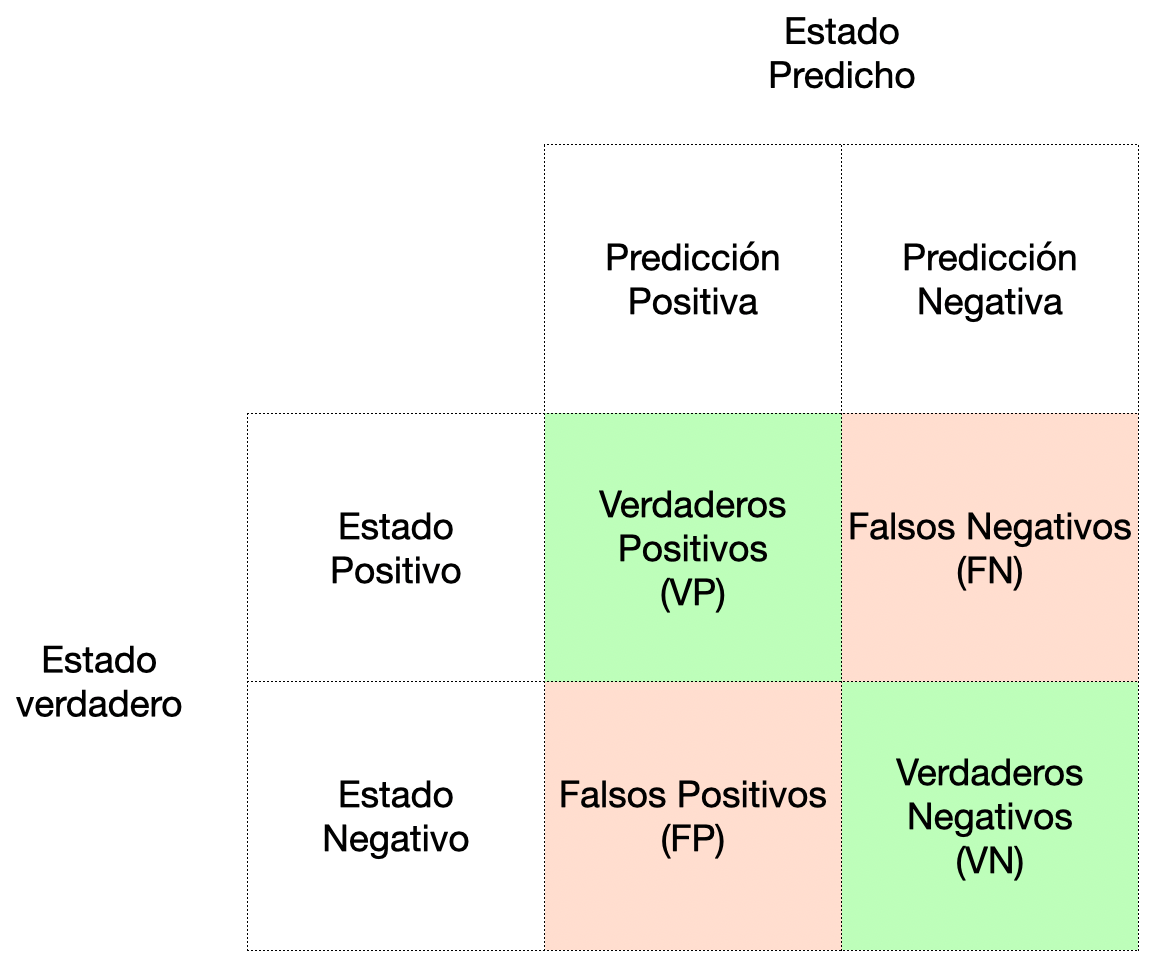

El objetivo principal de la matriz de confusión es obtener medidas para comparar los valores predecidos con los valores verdaderos
Lo que constituye una "buena" medida depende de la situación

Fecha de entrega: Abril 15, 2021. (Antes del inicio de la próxima clase)