¿Correo basura o no?¶
Clasificación de Textos (Parte 2)¶
NLP - Analítica Estratégica de Datos¶
Fundación Universitaria Konrad Lorenz
Docente: Viviana Márquez vivianam.penama@konradlorenz.edu.co
Clase #8 🥳: Abril 15, 2021
Fundación Universitaria Konrad Lorenz
Docente: Viviana Márquez vivianam.penama@konradlorenz.edu.co
Clase #8 🥳: Abril 15, 2021

 ¡Es un gato!
¡Es un gato!
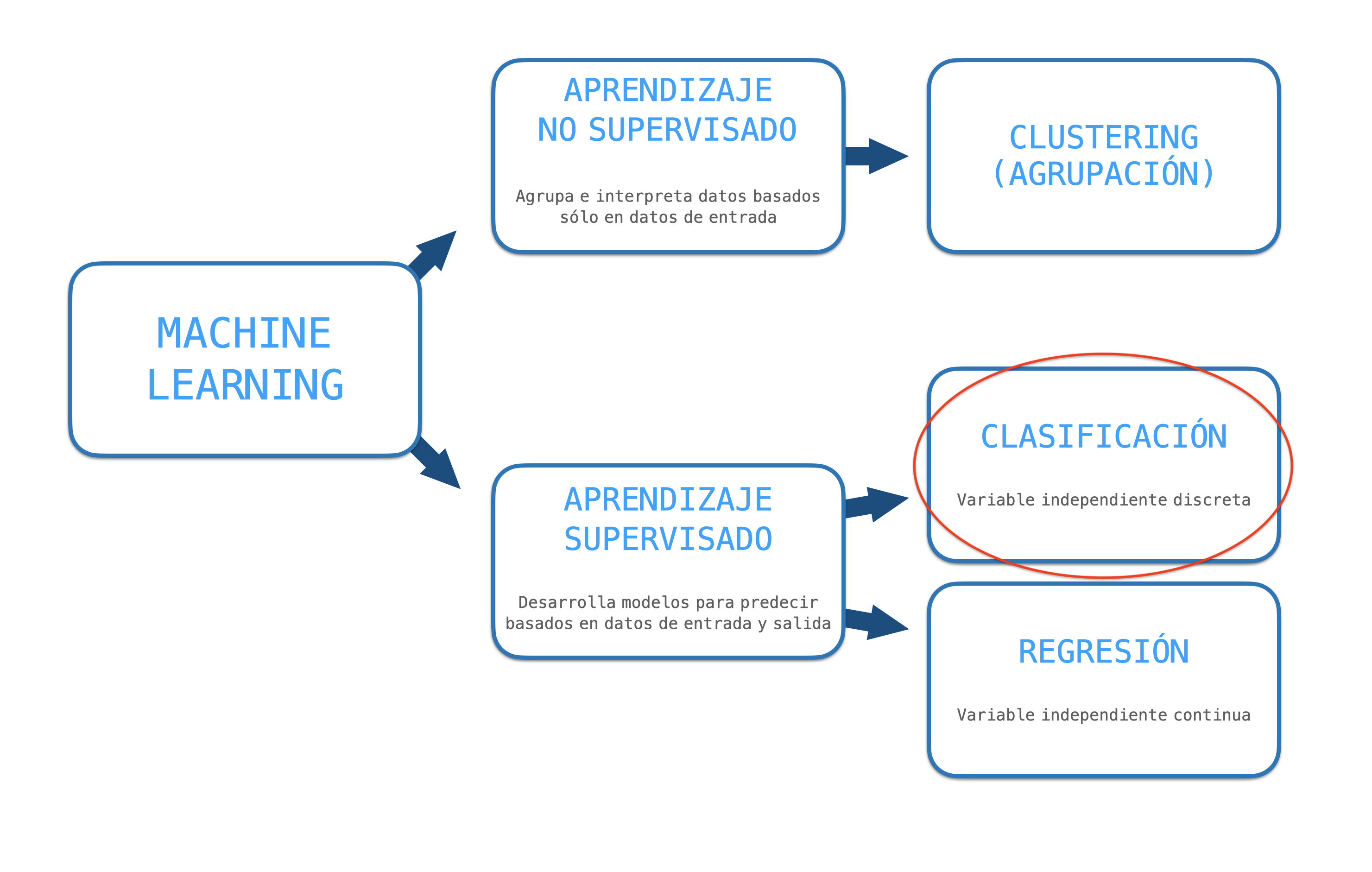
Se dividen en tres categorías:


• Es el modelo más famoso de Machine Learning después de la regresión lineal
• Mientras que la regresión lineal se usa para predecir/pronosticar valores continuos, la regresión logística se usa habitualmente para clasificar valores discretos.
• Las predicciones están mapeados entre 0 y 1 a través de la función logística, lo que significa que las predicciones pueden ser interpretadas como probabilidades.
👍 VENTAJAS:
overfitting)👎 DESVENTAJAS:
¿Cómo separarían estos datos de 1-dimensión en dos clases?

¿Cómo separarían estos datos de 2-dimensión en dos clases?

¿Cómo separarían datos de $n$-dimensión en dos clases?
Un punto/escalar en 1 dimensión
Una línea o una curva en 2 dimensiones
Un __ en dimensiones más altas.
Las MVS usan un mecanismo llamado kernel (ó núcleo) que esencialmente calcula la distancia entre dos observaciones. Con esto, el modelo encuentra un límite de decisión (hiperplano) óptimo para separar las clases.

Una MVS con un núcleo lineal es muy similar a la regresión logística, así que por lo general se usa con núcleos no-lineales con datos no-lineales

👍 VENTAJAS:
👎 DESVENTAJAS:

👍 VENTAJAS:
👎 DESVENTAJAS:

👍 VENTAJAS:
👎 DESVENTAJAS:
Pasos para un modelo de clasificación:
training) y prueba (test)import pandas as pd
data = pd.read_csv("../archivos/basura.csv")
data.head()
| mensaje | etiqueta | |
|---|---|---|
| 0 | ¡3 TEXTOS DEL TAROT GRATIS! ¡Descubre ahora tu... | basura |
| 1 | ¡No 1 tono POLIFÓNICO 4 ur mob cada semana! Si... | basura |
| 2 | Bienvenido a Select, un servicio O2 con benefi... | basura |
| 3 | Última oportunidad 2 reclame su valor de £ 150... | basura |
| 4 | Dorothy@kiefer.com (Bank of Granite emite Stro... | basura |
Entrenamiento (training) y prueba (test)
data.etiqueta.value_counts(normalize=True)
basura 0.550069 legítimo 0.449931 Name: etiqueta, dtype: float64
Estrategias para equilibrar el conjunto de datos:
Entrenamiento (training) y prueba (test). Usualmente 80% training y 20% test.
from sklearn.model_selection import train_test_split
train, test = train_test_split(data, test_size=0.2, random_state=42)
print(f"Tenemos {data.shape[0]} datos en total.")
print(f"El conjunto de datos de entrenamiento (train) tiene {train.shape[0]} datos.")
print(f"El conjunto de datos de prueba (test) tiene {test.shape[0]} datos.")
Tenemos 729 datos en total. El conjunto de datos de entrenamiento (train) tiene 583 datos. El conjunto de datos de prueba (test) tiene 146 datos.
import re
from nltk.corpus import stopwords
from sklearn.feature_extraction.text import TfidfVectorizer
stopwords_sp = stopwords.words('spanish')
def pre_procesado(texto):
texto = texto.lower()
texto = re.sub(r"[\W\d_]+", " ", texto)
texto = texto.split() # Tokenizar
texto = [palabra for palabra in texto if palabra not in stopwords_sp]
texto = " ".join(texto)
return texto
tfidf_vect = TfidfVectorizer(preprocessor=pre_procesado)
tfidf_vect.fit(train.mensaje.values);
X_train = tfidf_vect.transform(train.mensaje.values)
y_train = train.etiqueta.values
X_test = tfidf_vect.transform(test.mensaje.values)
y_test = test.etiqueta.values
print(f"Tamaño de X_train (entrenamiento): {pd.DataFrame(X_train.toarray()).shape}")
print(f"Tamaño de X_test (prueba): {pd.DataFrame(X_test.toarray()).shape}")
print(f"Tamaño de y_train {len(y_train)} y tamaño de y_test {len(y_test)}")
Tamaño de X_train (entrenamiento): (583, 2422) Tamaño de X_test (prueba): (146, 2422) Tamaño de y_train 583 y tamaño de y_test 146
from sklearn.naive_bayes import MultinomialNB
from sklearn.linear_model import LogisticRegression
from sklearn.svm import LinearSVC
from sklearn.tree import DecisionTreeClassifier
data
| mensaje | etiqueta | |
|---|---|---|
| 0 | ¡3 TEXTOS DEL TAROT GRATIS! ¡Descubre ahora tu... | basura |
| 1 | ¡No 1 tono POLIFÓNICO 4 ur mob cada semana! Si... | basura |
| 2 | Bienvenido a Select, un servicio O2 con benefi... | basura |
| 3 | Última oportunidad 2 reclame su valor de £ 150... | basura |
| 4 | Dorothy@kiefer.com (Bank of Granite emite Stro... | basura |
| 5 | Cámara: ¡se le otorga una cámara digital SiPix... | basura |
| 6 | MENSAJE GRATUITO: Facturamos su número de móvi... | basura |
| 7 | ¡Felicidades! El teléfono con cámara de video ... | basura |
| 8 | Compre hasta caer, ¿ES USTED? 10K, 5K, £ 500 e... | basura |
| 9 | ESPECIAL DE BONIFICACIÓN DE HMV Se pueden gana... | basura |
| 10 | ¡CABALLERO! Estamos intentando ponernos en con... | basura |
| 11 | ¡El premio urgente garantizado de £ 500 aún no... | basura |
| 12 | ¡USTED ES ELEGIDO PARA RECIBIR UN PREMIO DE £ ... | basura |
| 13 | Obtenga una película GRATUITA con un reproduct... | basura |
| 14 | Esta es la segunda vez que intentamos 2 contac... | basura |
| 15 | <Reenviado desde 21870000> Hola: esta es la al... | basura |
| 16 | ¡URGENTE! Estamos tratando de ponernos en cont... | basura |
| 17 | ¡Sorteos de premios de Navidad! Estamos intent... | basura |
| 18 | URGENTE Este es nuestro segundo intento de pon... | basura |
| 19 | ¡HAS GANADO! Sus vacaciones de 4 * en la Costa... | basura |
| 20 | ¡USTED HA GANADO! Como cliente valioso de Voda... | basura |
| 21 | ¡Última oportunidad! ¡Reclame hoy mismo cupone... | basura |
| 22 | Urgente Llame al 09066612661 desde el teléfono... | basura |
| 23 | ¡URGENTE! ¡Tu número de móvil 077xxx GANÓ un p... | basura |
| 24 | Entrada gratuita para la primera semana 2 TEXT... | basura |
| 25 | 500 nuevos móviles de 2004, ¡DEBEN IR! Envía u... | basura |
| 26 | ¿Quieres un nuevo teléfono de video? 750 en cu... | basura |
| 27 | Tienes 1 mensaje de voz nuevo. Llame al 087191... | basura |
| 28 | ¡Objetivo! Arsenal 4 (Henry, 7 v Liverpool 2 H... | basura |
| 29 | Préstamo para cualquier propósito entre £ 500 ... | basura |
| ... | ... | ... |
| 699 | Yo estamos viendo una película en netflix | legítimo |
| 700 | Okay. Todas las noches toma un baño tibio, beb... | legítimo |
| 701 | Un bloo bloo bloo, extrañaré el primer tazón | legítimo |
| 702 | Quiero kfc es martes. Solo compre 2 comidas SO... | legítimo |
| 703 | También maaaan te estás perdiendo | legítimo |
| 704 | No querida, estaba durmiendo :-P | legítimo |
| 705 | Tengo hambre comprar algo de comida buena lei ... | legítimo |
| 706 | Quiero mostrarte el mundo, princesa :) ¿Qué ta... | legítimo |
| 707 | ¿Entonces crees que debería hablar con él? ¿No... | legítimo |
| 708 | ¿Ahora tienes TV 2, mírame? ¿No trabajas hoy? | legítimo |
| 709 | Olol imprimí una publicación en el foro de un ... | legítimo |
| 710 | Luego ü pedirle a papá que recoja ü lar ... Ü ... | legítimo |
| 711 | Entonces, ¿tienes hombros de samus todavía? | legítimo |
| 712 | Olvidé decirle algo ... ¿Me gusta numerar las ... | legítimo |
| 713 | Lo siento, llamaré más tarde | legítimo |
| 714 | ¿No es esa época del mes ni la mitad del tiempo? | legítimo |
| 715 | ¿Cómo está mi amante? ¿Qué hace que le impida ... | legítimo |
| 716 | Hola. Ahora nos hemos mudado a nuestro pub. Se... | legítimo |
| 717 | Poema de la amistad: Querido O Querido U R No ... | legítimo |
| 718 | Sí, tenemos uno preparado para nosotros | legítimo |
| 719 | Prabha ... lo siento ... de verdad ... de cora... | legítimo |
| 720 | Ok, pero no demasiado temprano. Todavía tengo ... | legítimo |
| 721 | Seguramente el resultado ofrecerá :) | legítimo |
| 722 | Es cierto, querida ... me senté a orar por la ... | legítimo |
| 723 | Oye nena, mi amigo tuvo que cancelar, ¿todavía... | legítimo |
| 724 | Estoy en el hospital da. . Regresaré a casa po... | legítimo |
| 725 | Ü todos escriben o wat .. | legítimo |
| 726 | No puedo asumir ningún papel importante en el ... | legítimo |
| 727 | Ojalá estuviera contigo. Sosteniéndote fuerte.... | legítimo |
| 728 | Huh tan rápido ... ¿Eso significa que no has t... | legítimo |
729 rows × 2 columns
# Inicializar los clasificadores
nb = MultinomialNB()
logreg = LogisticRegression(class_weight='balanced')
svm = LinearSVC(class_weight='balanced')
dt = DecisionTreeClassifier(class_weight='balanced')
# Entrenamos los modelos
nb.fit(X_train, y_train)
logreg.fit(X_train, y_train)
svm.fit(X_train, y_train)
dt.fit(X_train, y_train);
pip install --upgrade scikit-learn
y_pred_nb = nb.predict(X_test)
y_pred_logreg = logreg.predict(X_test)
y_pred_svm = svm.predict(X_test)
y_pred_dt = dt.predict(X_test)
from sklearn.metrics import accuracy_score, f1_score
from sklearn.metrics import precision_score, recall_score
from sklearn.metrics import confusion_matrix, classification_report
import matplotlib.pyplot as plt
from sklearn.metrics import plot_confusion_matrix
print(f"Naive Bayes: {accuracy_score(y_test, y_pred_nb):>15.2f}")
print(f"Regresión Logística: {accuracy_score(y_test, y_pred_logreg):>7.2f}")
print(f"SVM: {accuracy_score(y_test, y_pred_svm):>23.2f}")
print(f"Árbol de decisión: {accuracy_score(y_test, y_pred_dt):>9.2f}")
Naive Bayes: 0.91 Regresión Logística: 0.97 SVM: 0.97 Árbol de decisión: 0.96
metricas = [precision_score, recall_score, f1_score]
for metrica in metricas:
print(metrica.__name__)
print(f"Naive Bayes: {metrica(y_test, y_pred_nb, pos_label='basura'):.2f}")
print(f"Regresión Logística: {metrica(y_test, y_pred_logreg, pos_label='basura'):.2f}")
print(f"SVM: {metrica(y_test, y_pred_svm, pos_label='basura'):.2f}")
print(f"Árbol de decisión: {metrica(y_test, y_pred_dt, pos_label='basura'):.2f}")
print()
precision_score Naive Bayes: 0.88 Regresión Logística: 0.98 SVM: 0.99 Árbol de decisión: 1.00 recall_score Naive Bayes: 0.99 Regresión Logística: 0.98 SVM: 0.97 Árbol de decisión: 0.93 f1_score Naive Bayes: 0.93 Regresión Logística: 0.98 SVM: 0.98 Árbol de decisión: 0.96
print("Naive Bayes")
print(classification_report(y_test, y_pred_nb))
print()
print("Regresión Logística")
print(classification_report(y_test, y_pred_logreg))
print()
print("SVM")
print(classification_report(y_test, y_pred_svm))
print()
print("Árbol de decisión")
print(classification_report(y_test, y_pred_dt))
print()
Naive Bayes
precision recall f1-score support
basura 0.88 0.99 0.93 86
legítimo 0.98 0.80 0.88 60
accuracy 0.91 146
macro avg 0.93 0.89 0.90 146
weighted avg 0.92 0.91 0.91 146
Regresión Logística
precision recall f1-score support
basura 0.98 0.98 0.98 86
legítimo 0.97 0.97 0.97 60
accuracy 0.97 146
macro avg 0.97 0.97 0.97 146
weighted avg 0.97 0.97 0.97 146
SVM
precision recall f1-score support
basura 0.99 0.97 0.98 86
legítimo 0.95 0.98 0.97 60
accuracy 0.97 146
macro avg 0.97 0.97 0.97 146
weighted avg 0.97 0.97 0.97 146
Árbol de decisión
precision recall f1-score support
basura 1.00 0.93 0.96 86
legítimo 0.91 1.00 0.95 60
accuracy 0.96 146
macro avg 0.95 0.97 0.96 146
weighted avg 0.96 0.96 0.96 146
confusion_matrix(y_test, y_pred_nb)
array([[85, 1],
[12, 48]])
%config InlineBackend.figure_format = 'svg'
fig = plt.figure(figsize=(10,10))
ax1 = fig.add_subplot(2,2,1)
plot_confusion_matrix(nb, X_test, y_test, cmap="Blues", ax=ax1, normalize='true').im_.colorbar.remove()
plt.title("Naive Bayes")
ax2 = fig.add_subplot(2,2,2)
plot_confusion_matrix(logreg, X_test, y_test, cmap = 'Blues', ax=ax2, normalize='true').im_.colorbar.remove()
plt.title("Regresión Logística")
ax3 = fig.add_subplot(2,2,3)
plot_confusion_matrix(svm, X_test, y_test, cmap = 'Blues', ax=ax3, normalize='true').im_.colorbar.remove()
plt.title("SVM");
ax4 = fig.add_subplot(2,2,4)
plot_confusion_matrix(dt, X_test, y_test, cmap = 'Blues', ax=ax4, normalize='true').im_.colorbar.remove()
plt.title("Árbol de decisión");
Resultados & explicación
# Resultados
nuevos = ['Hola tú, estás por ahí?', 'ENTRADAS GRATIS MARCANDO AL 5555']
nuevos_trans = tfidf_vect.transform(nuevos)
dt.predict(nuevos_trans)
# nb.predict_proba(nuevos_trans)
array(['legítimo', 'basura'], dtype=object)
# Explicación
vocab = {value:key for key,value in tfidf_vect.vocabulary_.items()}
vocab
{774: 'estimado',
2396: 'xxxxxxx',
1972: 'sido',
1083: 'invitado',
2384: 'xchat',
2417: 'último',
1080: 'intento',
420: 'contactarnos',
2212: 'txt',
301: 'chat',
1377: 'msgrcvdhg',
2069: 'suite',
1144: 'lands',
1887: 'row',
994: 'hl',
1151: 'ldn',
158: 'años',
1867: 'revisar',
1270: 'mantener',
816: 'fantástica',
413: 'consola',
1118: 'juegos',
1438: 'nokia',
881: 'gage',
335: 'club',
2318: 'visite',
2381: 'www',
340: 'cnupdates',
358: 'com',
1426: 'newsletter',
503: 'darse',
163: 'baja',
66: 'alertas',
1848: 'responder',
1526: 'palabra',
1519: 'out',
195: 'bloo',
803: 'extrañaré',
1689: 'primer',
2111: 'tazón',
908: 'generalmente',
2084: 'sustantivo',
1050: 'incontable',
577: 'diccionario',
1615: 'piezas',
1082: 'investigación',
862: 'freemsg',
1193: 'llamadas',
935: 'gratuitas',
1035: 'ilimitadas',
1325: 'mes',
20: 'activar',
2002: 'smartcall',
1202: 'llame',
1464: 'número',
2058: 'subscriptn',
903: 'gbp',
2369: 'wk',
149: 'ayuda',
2044: 'stop',
1143: 'landlineonly',
1979: 'signo',
1259: 'madurez',
685: 'empezamos',
523: 'decir',
930: 'grandes',
449: 'cosas',
1774: 'realidad',
709: 'entender',
1582: 'pequeñas',
204: 'bonita',
2103: 'tarde',
217: 'bslvyl',
1318: 'mensaje',
936: 'gratuito',
807: 'facturamos',
1402: 'móvil',
743: 'error',
497: 'código',
447: 'corto',
1813: 'reembolsen',
274: 'cargos',
1192: 'llamada',
934: 'gratuita',
2119: 'teléfono',
835: 'fijo',
219: 'bt',
464: 'créditos',
1777: 'recargado',
1015: 'http',
220: 'bubbletext',
1617: 'pin',
1829: 'renovación',
2142: 'tgxxrz',
886: 'ganador',
756: 'especialmente',
1932: 'seleccionado',
1781: 'recibe',
665: 'efectivo',
652: 'día',
829: 'festivo',
2337: 'vuelos',
1044: 'incluidos',
953: 'hable',
1499: 'operador',
2324: 'vivo',
1794: 'reclame',
1333: 'min',
733: 'envía',
1320: 'mensajes',
2137: 'texto',
400: 'conoce',
67: 'alguien',
1960: 'sexy',
1011: 'hoy',
1724: 'puede',
694: 'encontrar',
321: 'cita',
1046: 'incluso',
435: 'coquetear',
543: 'depende',
2419: 'únase',
2016: 'solo',
1844: 'responda',
1440: 'nombre',
663: 'edad',
669: 'ejemplo',
1911: 'sam',
1375: 'msg',
1778: 'recd',
2146: 'thirtyeight',
1575: 'pence',
1486: 'oh',
909: 'genial',
1358: 'molestaré',
1634: 'podamos',
952: 'hablar',
2115: 'tddnewsletter',
679: 'emc',
341: 'co',
2228: 'uk',
2144: 'thedailydraw',
1751: 'querida',
981: 'helen',
619: 'docenas',
933: 'gratis',
1679: 'premios',
1059: 'información',
2338: 'vuelta',
1244: 'lugar',
1524: 'padres',
2076: 'sur',
2099: 'tampa',
130: 'así',
1637: 'podría',
1415: 'necesitar',
958: 'hacer',
2197: 'trato',
1927: 'segunda',
2292: 'vez',
1078: 'intentamos',
885: 'ganado',
1678: 'premio',
1171: 'libras',
877: 'fácil',
54: 'ahora',
2105: 'tarifa',
1406: 'nacional',
1557: 'pasar',
1944: 'sentimiento',
587: 'diferente',
526: 'decisiones',
2261: 'vacilantes',
864: 'frente',
1339: 'mismas',
1340: 'mismo',
1055: 'individuo',
2150: 'tiempo',
484: 'curará',
460: 'creo',
1234: 'lol',
224: 'bueno',
966: 'hagas',
1638: 'podríamos',
2123: 'tener',
928: 'gran',
2281: 'venta',
1125: 'juntos',
884: 'gana',
1457: 'nuevo',
972: 'harry',
1663: 'potter',
1508: 'orden',
878: 'fénix',
1173: 'libro',
1846: 'responde',
1674: 'preguntas',
1500: 'oportunidad',
1952: 'ser',
1691: 'primero',
1158: 'lectores',
77: 'am',
1625: 'pm',
453: 'costo',
2241: 'ur',
1518: 'otorgó',
324: 'city',
211: 'break',
888: 'ganar',
1119: 'juerga',
378: 'compras',
2284: 'verano',
239: 'cada',
1937: 'semana',
2048: 'store',
1999: 'skilgme',
2207: 'tscs',
2367: 'winawk',
46: 'age',
2053: 'sub',
1653: 'ponernos',
422: 'contacto',
2251: 'usted',
1827: 'relación',
1479: 'oferta',
2302: 'videoteléfono',
470: 'cualquier',
1359: 'momento',
1812: 'red',
1342: 'mitad',
1668: 'precio',
654: 'dígale',
590: 'dije',
359: 'coma',
1330: 'mierda',
2306: 'viene',
1323: 'mente',
153: 'ayúdame',
376: 'comprar',
1584: 'percha',
382: 'computadora',
1656: 'portátil',
1603: 'pesa',
2366: 'win',
2039: 'sr',
849: 'foley',
891: 'ganó',
1085: 'ipod',
1715: 'próximamente',
682: 'emocionantes',
132: 'atento',
1005: 'hora',
459: 'crees',
1417: 'necesito',
1898: 'saber',
491: 'cuándo',
516: 'debería',
291: 'cerca',
257: 'campus',
711: 'entrada',
1690: 'primera',
2140: 'textpod',
902: 'gb',
735: 'envíe',
1633: 'pod',
2205: 'ts',
465: 'cs',
1421: 'net',
486: 'custcare',
893: 'garantizados',
2418: 'últimos',
2120: 'teléfonos',
1837: 'reproductor',
1373: 'mp',
2372: 'word',
354: 'collect',
2164: 'to',
2113: 'tc',
1207: 'llc',
1461: 'ny',
664: 'ee',
2257: 'uu',
1379: 'mt',
1376: 'msgrcvd',
2245: 'urgente',
1191: 'llama',
2260: 'vacaciones',
1025: 'ibiza',
758: 'espera',
1804: 'recolección',
1902: 'sae',
1627: 'po',
207: 'box',
1998: 'sk',
2375: 'wp',
1664: 'ppm',
1961: 'señor',
761: 'esperando',
441: 'correo',
1784: 'recibir',
317: 'cierren',
1255: 'líneas',
476: 'cuesta',
110: 'aplican',
2222: 'términos',
388: 'condiciones',
1702: 'promoción',
45: 'ag',
1331: 'miles',
307: 'chicas',
1384: 'muchas',
1228: 'locales',
2344: 'vírgenes',
1188: 'listo',
837: 'fil',
1412: 'necesidad',
1959: 'sexual',
1726: 'puedes',
838: 'filmar',
488: 'cute',
1000: 'holiday',
776: 'estrellas',
446: 'cortesía',
1413: 'necesita',
352: 'colección',
1142: 'landline',
1585: 'perder',
242: 'caja',
451: 'costa',
2010: 'sol',
52: 'aguardan',
1800: 'recogida',
1792: 'reclamar',
1628: 'pobox',
2043: 'stockport',
2386: 'xh',
1294: 'max',
1335: 'mins',
1290: 'masculina',
701: 'enero',
1009: 'hot',
899: 'gay',
171: 'barato',
1609: 'pico',
569: 'detener',
1695: 'privado',
473: 'cuenta',
852: 'fone',
1389: 'muestra',
1732: 'puntos',
264: 'canjeados',
1030: 'identificación',
2276: 'vence',
115: 'aquí',
2118: 'televisión',
1973: 'siempre',
611: 'disponible',
2187: 'trabajo',
565: 'después',
534: 'dejé',
1980: 'sigo',
32: 'adelante',
1337: 'minutos',
36: 'adivina',
405: 'conoces',
1921: 'secretamente',
946: 'gusta',
1755: 'quieres',
1760: 'quién',
1223: 'llámanos',
508: 'datebox',
767: 'essexcm',
2388: 'xn',
492: 'cuánto',
452: 'costaría',
429: 'contratar',
1971: 'sicario',
375: 'comprado',
1127: 'juz',
1217: 'llegó',
999: 'hola',
1838: 'reservado',
1156: 'lecciones',
2071: 'sun',
1168: 'liao',
882: 'galardonado',
892: 'garantizado',
1790: 'reclamación',
2342: 'válido',
1007: 'horas',
1928: 'segundo',
147: 'ayer',
159: 'aún',
1576: 'pendiente',
1801: 'recogido',
1756: 'quiero',
555: 'descuento',
1481: 'oficial',
39: 'aduanas',
1177: 'life',
1460: 'nunca',
2101: 'tan',
615: 'divertido',
714: 'entraste',
992: 'hiciste',
1776: 'realmente',
754: 'especial',
1493: 'olvidaré',
604: 'disfruta',
1497: 'one',
2004: 'sms',
840: 'final',
482: 'cupones',
2266: 'valor',
1918: 'savamob',
1480: 'ofertas',
1328: 'miembros',
1403: 'móviles',
2258: 'uz',
2079: 'suscripción',
1482: 'oficina',
1820: 'regazo',
950: 'habitación',
653: 'días',
293: 'cerré',
428: 'contraseña',
1321: 'mensual',
2352: 'wap',
1353: 'mobsi',
2255: 'utilice',
1566: 'pc',
2054: 'subasta',
2420: 'únete',
1547: 'participa',
2347: 'wah',
43: 'afortunado',
710: 'entonces',
55: 'ahorrar',
593: 'dinero',
1107: 'je',
2333: 'voy',
2280: 'venir',
1086: 'ir',
1368: 'morrow',
1090: 'iré',
1473: 'obtuve',
591: 'dijo',
1431: 'ningún',
1712: 'préstamo',
1708: 'propósito',
1704: 'propietarios',
1074: 'inquilinos',
189: 'bienvenidos',
1779: 'rechazado',
96: 'anteriormente',
2167: 'todavía',
1635: 'podemos',
150: 'ayudar',
2131: 'termine',
2027: 'soplarme',
1571: 'pelo',
2130: 'terminaste',
288: 'cenar',
830: 'fidelización',
332: 'cliente',
2093: 'sólo',
2213: 'txtauction',
2041: 'start',
1474: 'obtén',
468: 'ctxt',
1380: 'mtmsg',
1296: 'mayor',
2297: 'vida',
1977: 'significa',
82: 'ame',
1991: 'sino',
86: 'amo',
1601: 'personas',
1394: 'mundo',
84: 'amigos',
1203: 'llamo',
905: 'ge',
1552: 'parís',
1884: 'romántico',
1435: 'noches',
1840: 'reserve',
1717: 'próximo',
157: 'año',
1345: 'mmm',
1570: 'pediste',
1195: 'llamara',
1765: 'radio',
1955: 'servicio',
323: 'citas',
418: 'contactando',
2141: 'tg',
1369: 'mostrarte',
1693: 'princesa',
2096: 'tal',
786: 'europa',
73: 'alojamiento',
746: 'escapadas',
1795: 'reclamo',
513: 'debe',
1707: 'proporcionar',
427: 'contrario',
1293: 'matrícula',
1538: 'parcial',
496: 'cámara',
589: 'digital',
1472: 'obtiene',
1548: 'participar',
2114: 'tcr',
1023: 'ibh',
1154: 'lealtad',
1351: 'mobile',
227: 'burger',
1135: 'king',
1123: 'jugar',
879: 'fútbol',
771: 'estadio',
2074: 'superior',
1951: 'septiembre',
976: 'hazte',
929: 'grande',
2094: 'súper',
346: 'coca',
350: 'cola',
1835: 'representante',
1194: 'llamar',
1108: 'jefe',
1300: 'mañana',
1555: 'pasado',
657: 'dónde',
1640: 'podía',
118: 'arreglar',
136: 'auto',
530: 'dejaba',
525: 'decirme',
759: 'esperaba',
2330: 'volviera',
498: 'cómo',
119: 'arrepintió',
948: 'haber',
1783: 'recibido',
782: 'etc',
1567: 'pedido',
421: 'contacte',
1727: 'puedo',
37: 'adivinar',
1864: 'revelado',
2379: 'wu',
1683: 'prepare',
1104: 'jardín',
1934: 'selección',
226: 'bulbos',
1942: 'semillas',
2143: 'the',
1919: 'scotsman',
2089: 'sábado',
918: 'go',
1450: 'notxt',
944: 'guauu',
309: 'chicos',
162: 'back',
965: 'haga',
914: 'gira',
1825: 'reino',
2234: 'unido',
890: 'gane',
201: 'boletos',
2313: 'vip',
97: 'anticipación',
2188: 'trackmarque',
1242: 'ltd',
1058: 'info',
2314: 'vipclub',
1824: 'regreso',
1120: 'jueves',
1019: 'hurra',
2259: 'va',
187: 'bien',
408: 'conseguir',
1910: 'salud',
1970: 'si',
752: 'escuela',
1200: 'llamas',
1477: 'ocurren',
1029: 'ideas',
2135: 'textbuddy',
238: 'cachondos',
116: 'area',
1782: 'reciben',
230: 'buscar',
1662: 'postal',
901: 'gaytextbuddy',
1326: 'meses',
74: 'alquiler',
1254: 'línea',
1408: 'naranja',
598: 'direct',
27: 'actualizar',
887: 'ganamos',
1139: 'lado',
440: 'corregir',
1513: 'ortografía',
1915: 'sarcasmo',
764: 'espero',
605: 'disfrutado',
423: 'contenido',
261: 'cancelar',
1706: 'proporcionado',
2176: 'tones',
2403: 'you',
205: 'bono',
1287: 'marsms',
1069: 'inicie',
1957: 'sesión',
2254: 'utele',
1469: 'obtener',
463: 'crédito',
1853: 'respuesta',
571: 'deténgase',
131: 'atención',
857: 'fps',
1573: 'película',
1199: 'llamaré',
8: 'acabo',
443: 'correr',
606: 'disfrutaste',
387: 'concierto',
2175: 'tone',
1350: 'mob',
1988: 'simplemente',
1780: 'reciba',
655: 'dígaselo',
913: 'getzed',
2376: 'wq',
1442: 'norm',
1516: 'otorga',
1992: 'sipix',
867: 'fromm',
715: 'entrega',
1489: 'okay',
2348: 'wahala',
1809: 'recuerda',
83: 'amigo',
1414: 'necesitado',
625: 'donar',
772: 'esterlinas',
851: 'fondo',
111: 'apoyo',
549: 'desastres',
2208: 'tsunami',
124: 'asiático',
2233: 'unicef',
724: 'enviando',
626: 'donate',
156: 'añadirán',
1714: 'próxima',
805: 'factura',
1577: 'peniques',
1336: 'minuto',
64: 'alemania',
1622: 'planettalkinstant',
1975: 'siento',
2145: 'themob',
660: 'echa',
2320: 'vistazo',
1789: 'reciente',
2179: 'tonos',
310: 'chismes',
544: 'deporte',
1273: 'mantén',
854: 'forma',
1512: 'original',
1553: 'pasa',
275: 'cariño',
250: 'callas',
2125: 'tenso',
2223: 'tía',
1016: 'huai',
1116: 'juan',
425: 'contesta',
2159: 'titular',
483: 'cupón',
2160: 'tlp',
1870: 'reward',
825: 'felicidades',
2298: 'video',
477: 'cuestan',
140: 'ave',
2269: 'varían',
292: 'cerrar',
1661: 'post',
177: 'bcm',
2356: 'wc',
2390: 'xx',
2351: 'wan',
1308: 'meet',
941: 'greet',
2362: 'westlife',
28: 'actualmente',
1087: 'irrompible',
1056: 'indomable',
556: 'descuidado',
780: 'estándar',
152: 'ayudarte',
228: 'bus',
2279: 'vengo',
1703: 'pronto',
2278: 'vendré',
996: 'ho',
2249: 'usas',
2155: 'tipo',
1527: 'palabras',
819: 'favor',
738: 'envíes',
1788: 'recibo',
1733: 'pureza',
85: 'amistad',
630: 'dos',
2193: 'trata',
2022: 'sonreír',
1159: 'leer',
1815: 'reenviado',
2283: 'ver',
945: 'gud',
788: 'evng',
12: 'aceptar',
13: 'aceptas',
988: 'hermano',
1996: 'sister',
80: 'amante',
1752: 'querido',
1312: 'mejor',
334: 'clos',
1251: 'lvblefrnd',
1115: 'jstfrnd',
489: 'cutefrnd',
1178: 'lifpartnr',
78: 'amado',
1889: 'rply',
699: 'enemigo',
2112: 'tbs',
1594: 'persolvo',
1593: 'persiguiendo',
528: 'definitivamente',
1525: 'pagando',
926: 'gracias',
1034: 'ignoraremos',
1131: 'kath',
1267: 'manchester',
1467: 'objetivo',
121: 'arsenal',
986: 'henry',
1190: 'liverpool',
93: 'anota',
1987: 'simple',
610: 'disparo',
2400: 'yardas',
1559: 'pase',
183: 'bergkamp',
502: 'darle',
1281: 'margen',
921: 'goles',
1371: 'motorola',
2180: 'tooth',
1352: 'mobileupd',
1503: 'optout',
2380: 'wv',
506: 'das',
90: 'ancianas',
445: 'corriendo',
2109: 'tatuajes',
419: 'contactar',
466: 'csbcm',
251: 'callcost',
1665: 'ppmmobilesvary',
1397: 'máximo',
289: 'centavo',
834: 'fija',
2200: 'través',
9: 'acceso',
1681: 'prepago',
601: 'directo',
2116: 'telediscount',
725: 'enviar',
1670: 'pregunta',
949: 'habilidades',
1322: 'mentales',
520: 'debo',
729: 'enviarte',
856: 'fotos',
2199: 'traviesas',
1791: 'reclamado',
822: 'fecha',
316: 'cierre',
1626: 'pmmás',
536: 'demobile',
212: 'bremoved',
1356: 'mobypobox',
1241: 'ls',
2401: 'yf',
1905: 'saldo',
1295: 'maximizar',
1068: 'ingreso',
282: 'cc',
203: 'bonificación',
308: 'chico',
1742: 'quedan',
644: 'dulces',
2083: 'suspiros',
87: 'amor',
687: 'empezaste',
779: 'estudiar',
2091: 'sé',
1982: 'sigues',
583: 'diciendo',
1386: 'mudó',
1925: 'seguimos',
314: 'chocando',
1169: 'libertad',
1852: 'responsabilidad',
265: 'cansado',
2102: 'tantas',
1176: 'lidiar',
106: 'apenas',
1271: 'mantengo',
51: 'agrega',
1038: 'importante',
2253: 'usuario',
2064: 'suerte',
554: 'descubre',
1064: 'ingresa',
2242: 'urawinner',
2030: 'sorpresa',
285: 'celda',
596: 'dip',
1387: 'muerta',
1845: 'respondas',
2329: 'volveremos',
1698: 'probando',
839: 'fin',
38: 'admirador',
1922: 'secreto',
229: 'buscando',
1654: 'ponerse',
144: 'averiguar',
1866: 'revelar',
1611: 'piensa',
2270: 'vas',
1363: 'montar',
186: 'bicicleta',
65: 'alerta',
1319: 'mensajería',
232: 'buzón',
1551: 'partidos',
2339: 'vuelva',
1811: 'recuperar',
349: 'coincidencias',
2170: 'tomando',
1306: 'medio',
1174: 'licencia',
2265: 'valioso',
371: 'complace',
1061: 'informarle',
1869: 'revisión',
1517: 'otorgará',
1071: 'inmediatamente',
765: 'esperándolo',
661: 'echar',
1647: 'polvo',
737: 'envíen',
2227: 'ubicaciones',
1773: 'reales',
1592: 'perros',
600: 'directamente',
1462: 'nyt',
659: 'ec',
1240: 'lp',
1487: 'ojalá',
426: 'contigo',
2034: 'sosteniéndote',
870: 'fuerte',
963: 'haciéndote',
1978: 'significas',
414: 'consultar',
192: 'biz',
708: 'enserio',
58: 'aire',
2097: 'talento',
1213: 'llegaste',
1017: 'huerto',
712: 'entradas',
1913: 'san',
2263: 'valentín',
478: 'cuestionario',
1219: 'lleve',
1542: 'pareja',
2294: 'viaje',
1770: 'rcvd',
995: 'hmv',
1725: 'pueden',
2264: 'vales',
911: 'genuinos',
1943: 'sencillas',
1836: 'reproducir',
1583: 'percent',
1772: 'real',
1246: 'lujoso',
1094: 'islas',
260: 'canarias',
114: 'aq',
1465: 'números',
24: 'actuales',
2327: 'vodafone',
2128: 'terminan',
1933: 'seleccionan',
347: 'coincide',
1556: 'pasamos',
255: 'camino',
1028: 'ideal',
104: 'aparezca',
1492: 'olvidamos',
256: 'caminos',
957: 'hacen',
252: 'caminando',
223: 'buenas',
1276: 'maravillas',
1349: 'mo',
773: 'estilo',
2023: 'sonrisa',
1598: 'personalidad',
1410: 'naturaleza',
1239: 'lovely',
866: 'friendship',
225: 'buenos',
564: 'despues',
2070: 'suministro',
99: 'anual',
283: 'cd',
2152: 'tienda',
670: 'elección',
1067: 'ingrese',
2032: 'sorteo',
1938: 'semanal',
1396: 'music',
1150: 'ldew',
2056: 'subs',
1666: 'ppmx',
59: 'aiyo',
789: 'ex',
1311: 'mei',
1850: 'respondido',
1849: 'respondes',
1894: 'rápido',
2186: 'trabajes',
667: 'eh',
169: 'bao',
2068: 'sugardad',
53: 'ah',
906: 'gee',
810: 'falso',
2326: 'voda',
2394: 'xxxx',
348: 'coincidencia',
322: 'citando',
109: 'aplicación',
2106: 'tarifas',
196: 'bloomberg',
290: 'centro',
763: 'esperar',
2013: 'solicite',
874: 'futuras',
278: 'carreras',
1378: 'msgs',
1444: 'not',
2153: 'time',
1562: 'pass',
579: 'dicen',
1985: 'silencio',
1579: 'pensando',
1612: 'piense',
1317: 'menos',
904: 'gd',
1453: 'nt',
2088: 'swt',
639: 'drms',
1963: 'shesil',
651: 'déjame',
1798: 'recoger',
234: 'básicamente',
1172: 'libre',
1941: 'semestre',
548: 'derecho',
357: 'color',
2238: 'update',
982: 'helens',
1713: 'príncipes',
...}
# Las palabras que contribuyen a la clase 1
[(vocab[e[0]], round(e[1],2)) for e in zip(svm.coef_[0].argsort(), sorted(logreg.coef_[0]))][:10]
[('llame', -3.06),
('txt', -1.74),
('com', -1.55),
('envíe', -1.5),
('envía', -1.49),
('gratis', -1.47),
('www', -1.45),
('texto', -1.3),
('premio', -1.24),
('uk', -1.23)]
[(vocab[e[0]],round(e[1],2)) for e in zip(dt.feature_importances_.argsort(), sorted(dt.feature_importances_))][-10:]
[('detener', 0.02),
('sms', 0.03),
('gratis', 0.03),
('com', 0.03),
('llama', 0.06),
('txt', 0.08),
('envía', 0.08),
('www', 0.08),
('envíe', 0.11),
('llame', 0.2)]
pip install graphviz sudo apt-get install graphvizconda install graphvizimport graphviz
from sklearn.tree import export_graphviz
viz = export_graphviz(dt,
out_file=None, # ¿Salvar en el computador?
max_depth=5, # Máxima profundidad
feature_names=list(dict(sorted(tfidf_vect.vocabulary_.items())).keys()), # Palabras
class_names = ['basura', 'legítimo'],
rounded=True, filled=True
)
graph = graphviz.Source(viz)
graph
Warning: Could not load "/usr/local/Cellar/graphviz/2.47.0/lib/graphviz/libgvplugin_pango.6.dylib" - It was found, so perhaps one of its dependents was not. Try ldd.

Taller # 7: Clasificación de textos
Fecha de entrega: Abril 22, 2021. (Antes del inicio de la próxima clase)
import pickle
with open('mimodelo.pkl', 'wb') as f:
pickle.dump(logreg, f)
with open('mimodelo.pkl', 'rb') as f:
mimodelo = pickle.load(f)