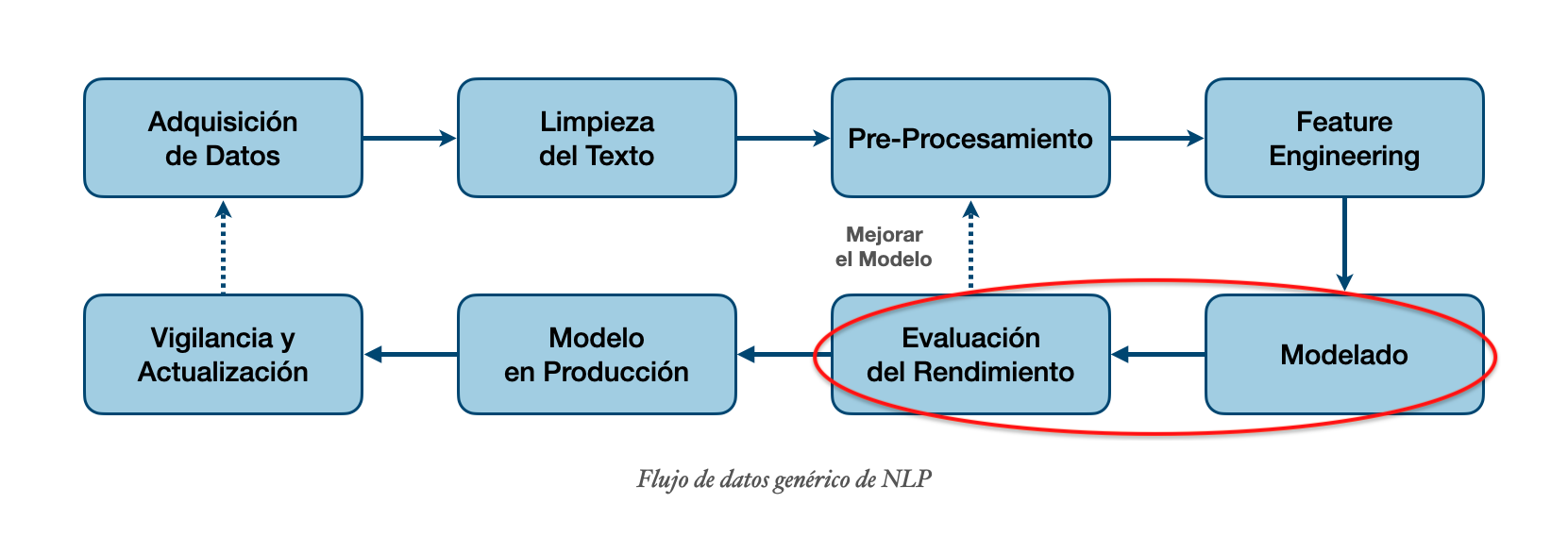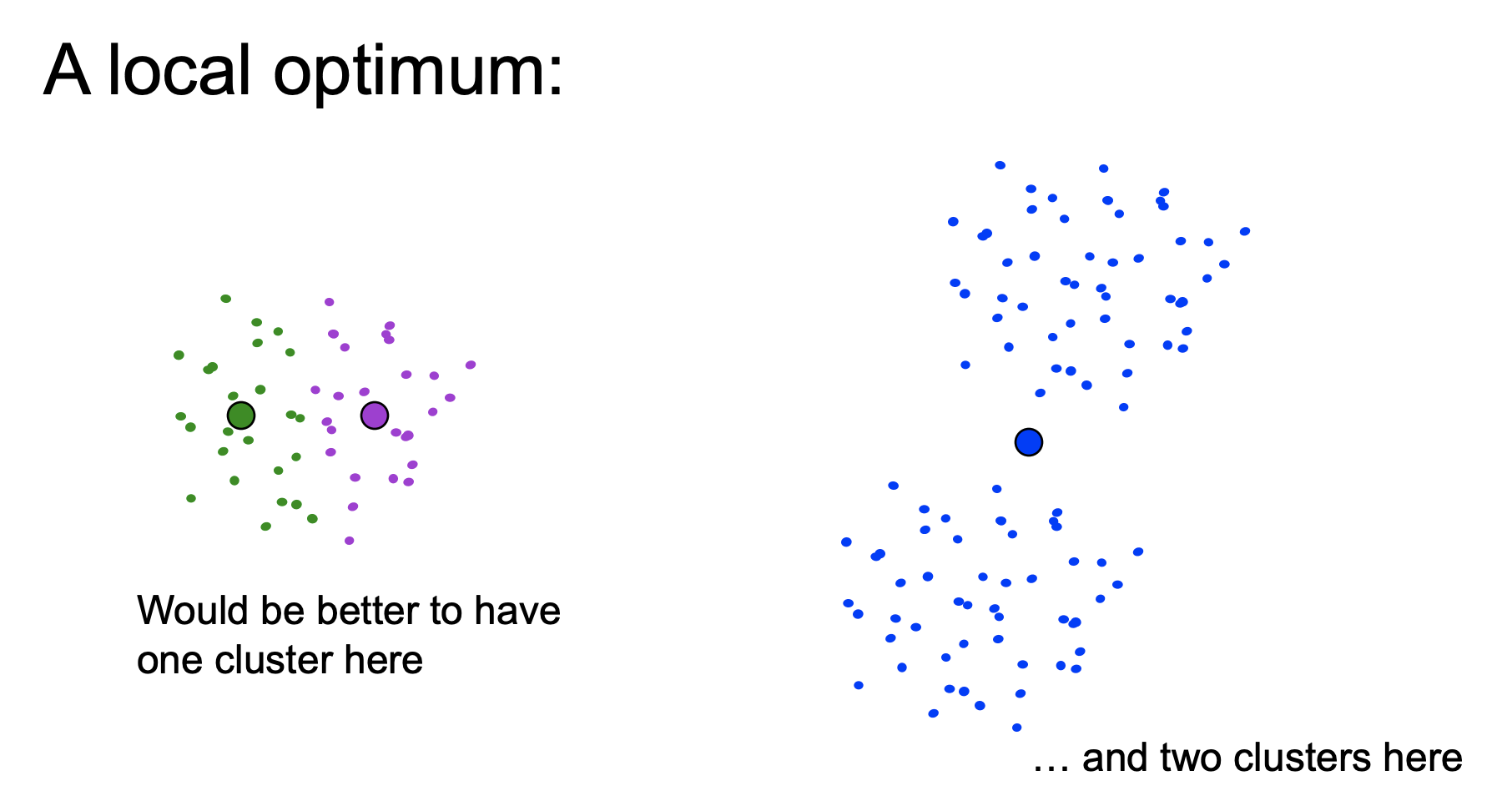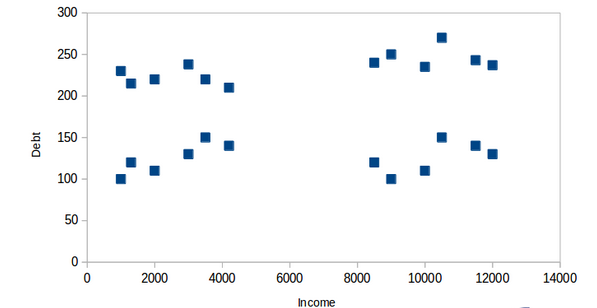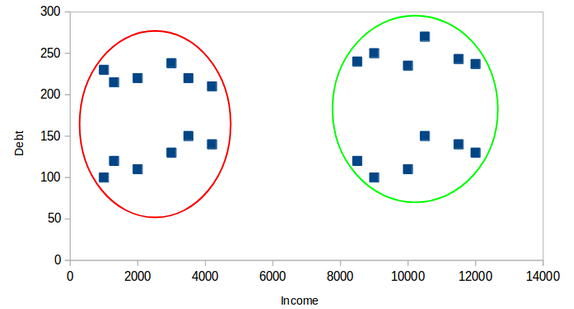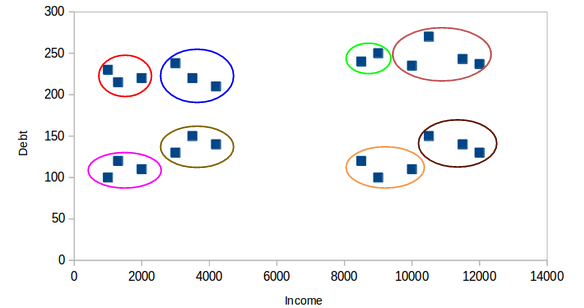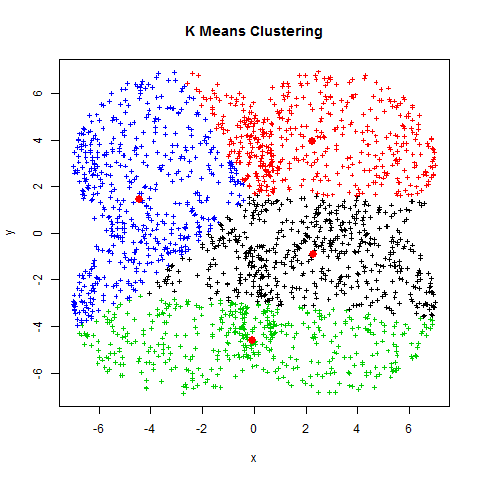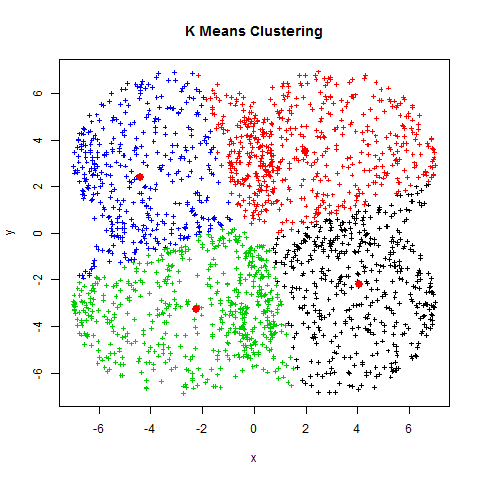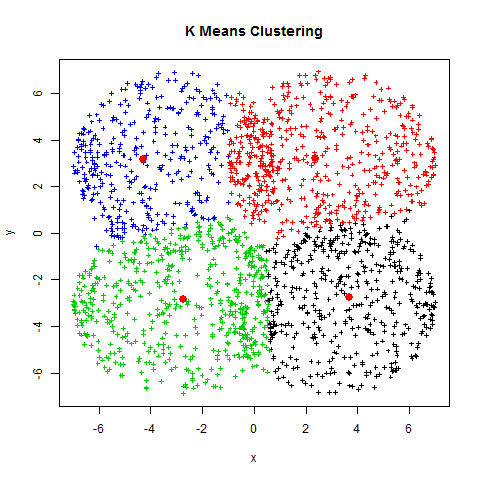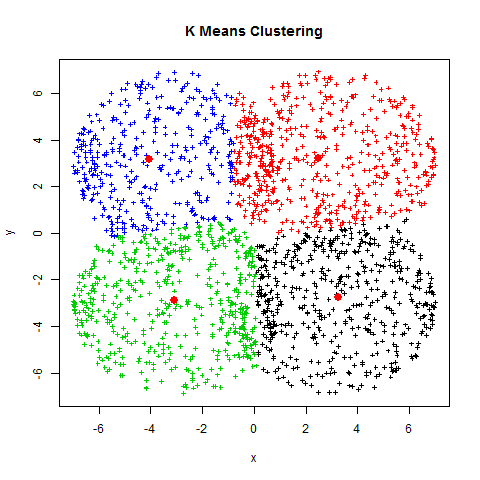
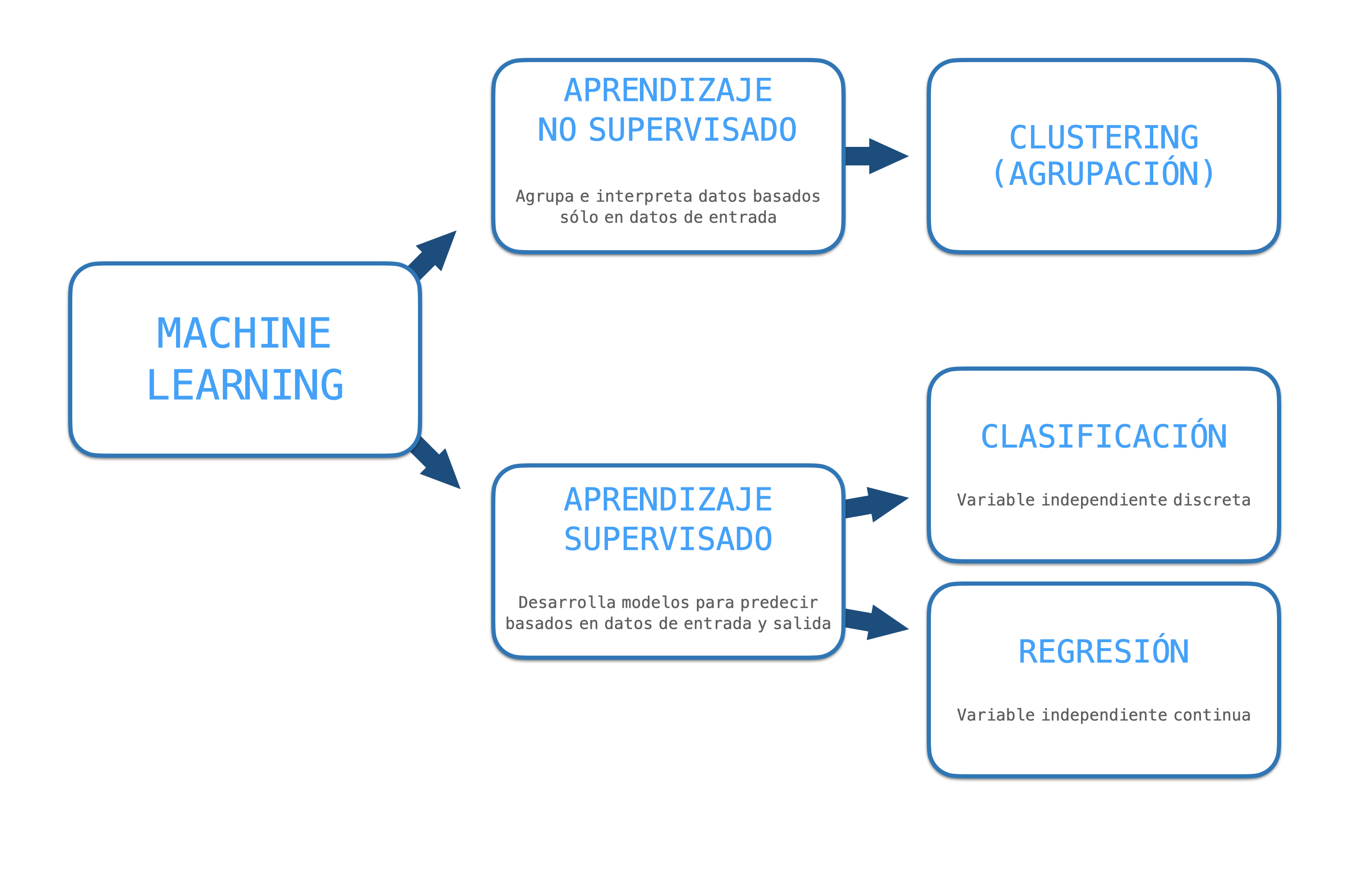
Agrupación de Textos¶
NLP - Analítica Estratégica de Datos¶
Fundación Universitaria Konrad Lorenz
Docente: Viviana Márquez vivianam.penama@konradlorenz.edu.co
Clase #9: April 22, 2020
class color:
PURPLE = '\033[95m'
CYAN = '\033[96m'
DARKCYAN = '\033[36m'
BLUE = '\033[94m'
GREEN = '\033[92m'
YELLOW = '\033[93m'
RED = '\033[91m'
BOLD = '\033[1m'
UNDERLINE = '\033[4m'
END = '\033[0m'
Fundación Universitaria Konrad Lorenz
Docente: Viviana Márquez vivianam.penama@konradlorenz.edu.co
Clase #9: April 22, 2020

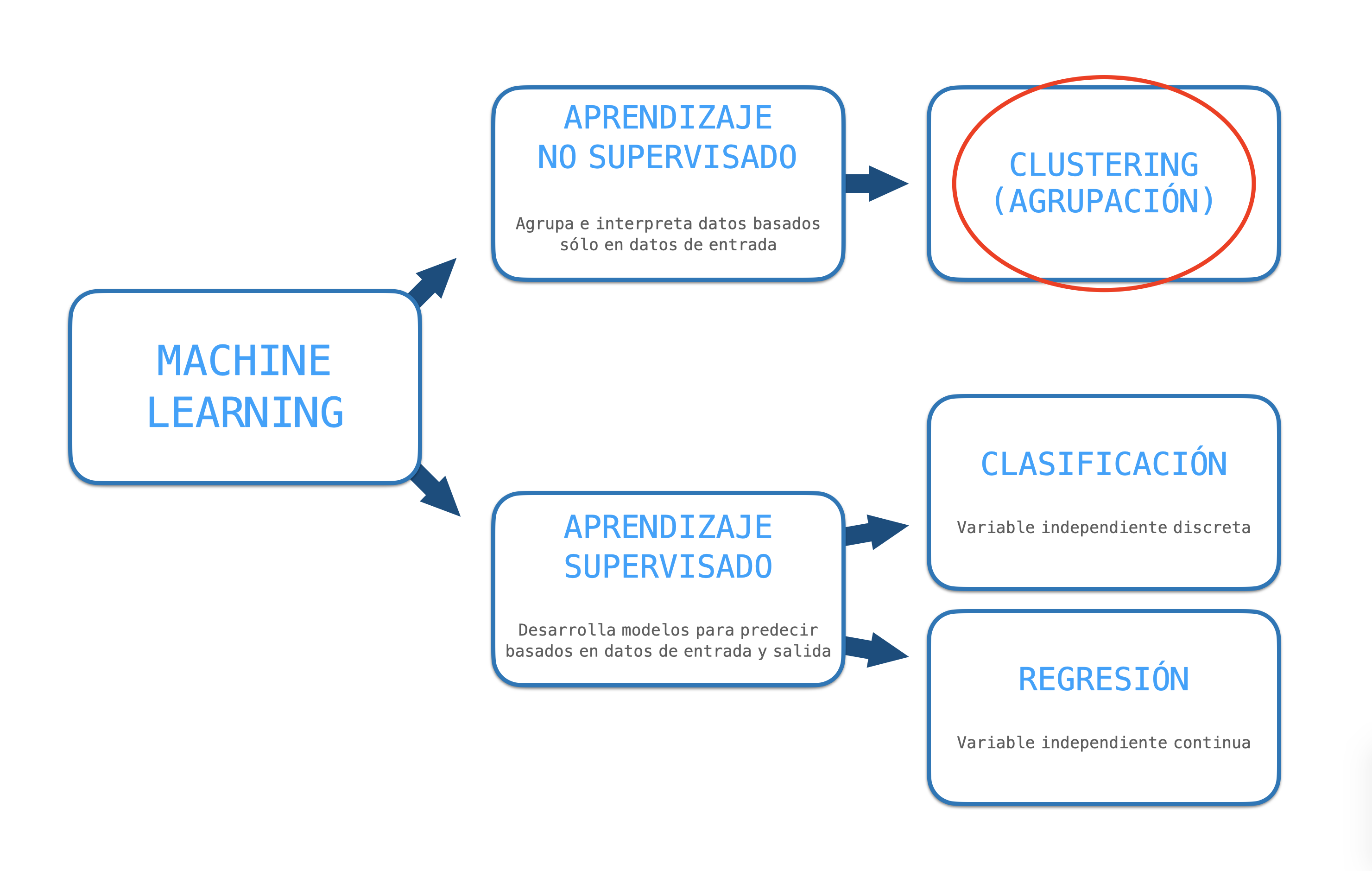
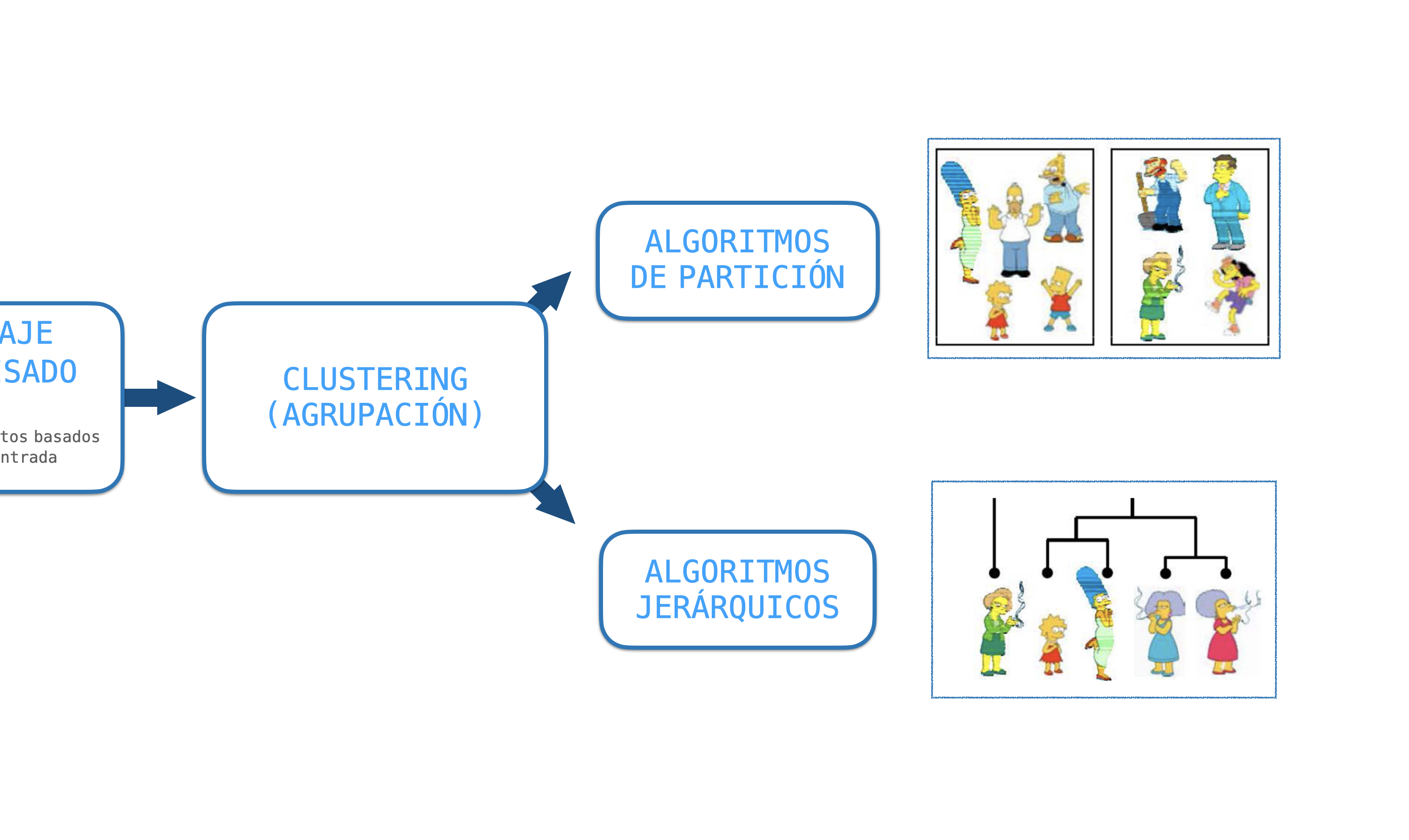
Es la forma más común de aprendizaje no supervisado
• Muestras de entrenamiento $\{ x_1, \ldots, x_n\} \in \mathbb{R}^{n}$
• No necesitamos (tenemos) etiquetas $y_i$
 • En la década de 1850, un médico de Londres llamado John Snow, graficó la ubicación de las muertes por cólera en un mapa.
• En la década de 1850, un médico de Londres llamado John Snow, graficó la ubicación de las muertes por cólera en un mapa.
• Las ubicaciones mostraron que los casos estaban agrupados cerca ciertas intersecciones donde habían pozos contaminados -- así, exponiendo tanto el problema como la solución.
 Fuente: Nina Mishra HP Labs
Fuente: Nina Mishra HP LabsObjetivo: Agrupar ejemplares en clases de objetos similares-- "cúmulos/clusters"
¿Cuándo usarlos? Cuando no sabemos qué estamos buscando
... pero, ¡cuidado, se puede convertir en galimatías!
El conjuto de datos debe tener:
- Alta similaridad intra-clases
- Baja similaridad inter-clases
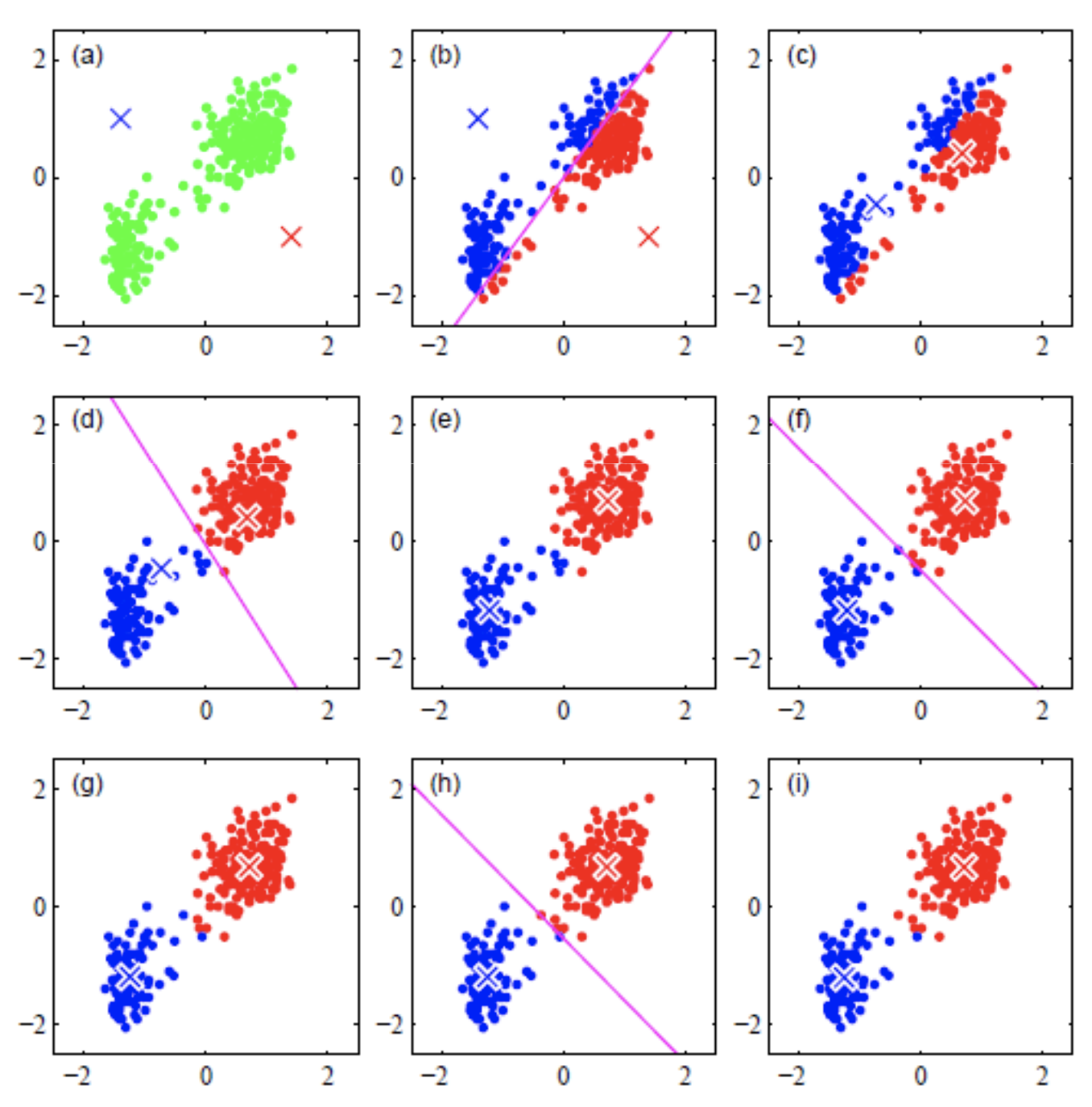
(También conocido como K-medias)
Modelo de Machine Learning NO supervisado de agrupación por partición
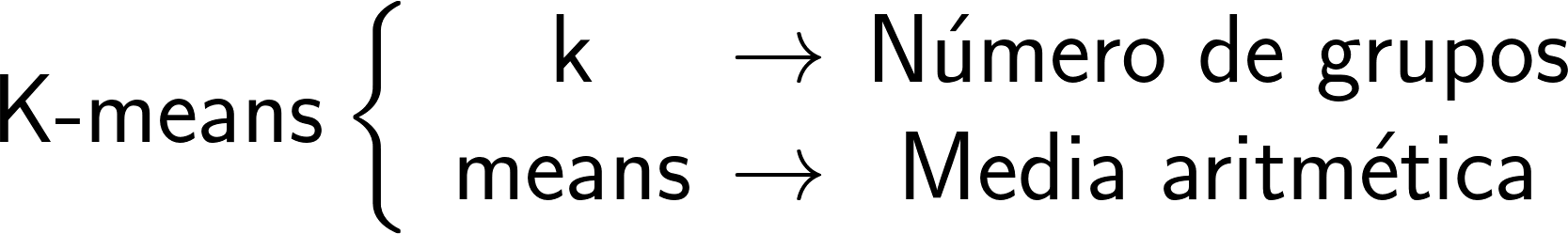
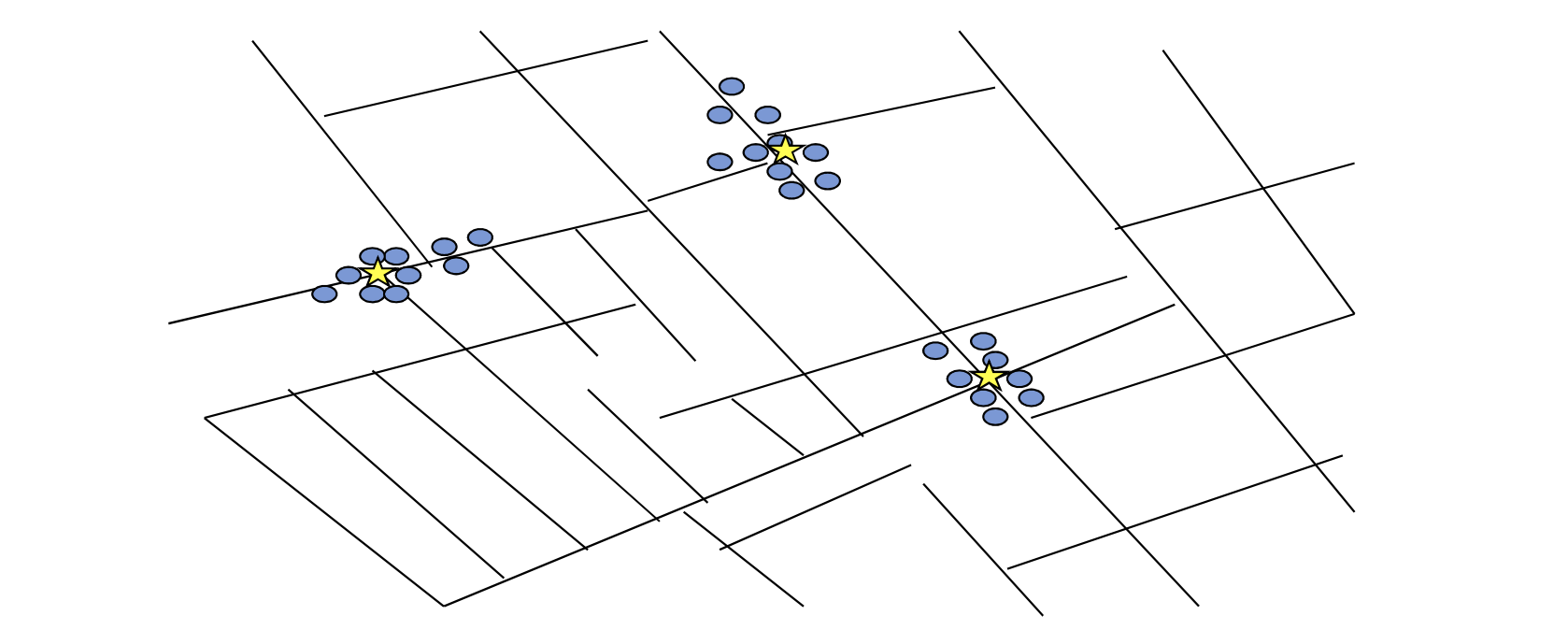
1. Inicializar
A. Elegir un número K de cúmulos
B. Escoger aleatoriamente K puntos como centroides
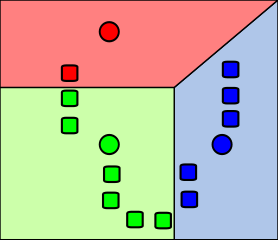

2. Repetir
A. Los K cúmulos se crean asociando cada observación con la media más cercana
B. El nuevo centroide de cada uno de los K cúmulos es la media de sus observaciones

3. Parar
A. Repetir pasos 1 y 2
B. El algoritmo acaba cuando ya no hay cambio en los centroides de los cúmulos, las observaciones de los cúmulos siguen siendo las mismas, o el máximo número de iteraciones es alcanzado
Paso 1: Cargar los datos
import pandas as pd
data = pd.read_csv("../archivos/lang_clase.csv")
print(f"Tenemos {data.shape[0]} registros.")
data.sample(5)
Tenemos 1000 registros.
| Text | |
|---|---|
| 642 | оба наиболее знаменитых трактата луиса де гран... |
| 273 | as criticas aos vídeos assistidos pelos rapaze... |
| 899 | la idea de un único emperador soberano se sust... |
| 204 | se trata de un edificio compuesto de tres volú... |
| 18 | los individuos eligen entonces los padres o tu... |
Paso 2: Feature Engineering
import re
from sklearn.feature_extraction.text import TfidfVectorizer
def pre_procesado(texto):
texto = texto.lower()
texto = re.sub(r"[\W\d]+", " ", texto)
return texto
tfidf_vect = TfidfVectorizer(preprocessor=pre_procesado)
tfidf = tfidf_vect.fit_transform(data.Text.values)
tfidf_matrix = pd.DataFrame(tfidf.toarray(), columns = tfidf_vect.get_feature_names())
Paso 2: Entrenar el modelo
Pero primero tenemos que escoger $K$
from sklearn.cluster import KMeans
from sklearn.neighbors import NearestNeighbors
import matplotlib.pyplot as plt
ks = []
k_inertias = []
for k in range(1,10):
kmeans = KMeans(n_clusters=k).fit(tfidf_matrix)
k_inertia = kmeans.inertia_
ks.append(k)
k_inertias.append(k_inertia)
# list(zip(ks,k_inertias))
plt.xlabel("Número de cúmulos")
plt.ylabel("Inercia")
plt.title("Método del codo")
plt.plot(ks, k_inertias, 'bx-');

k = 4
model = KMeans(n_clusters=k)
model.fit(tfidf_matrix)
KMeans(n_clusters=4)
data['cluster'] = model.labels_
data
| Text | cluster | |
|---|---|---|
| 0 | a cada etapa do circuito brasileiro banco do b... | 3 |
| 1 | мини-бар — небольшой холодильник с напитками п... | 0 |
| 2 | ломоносов м в «письмо и и шувалову от года» ... | 0 |
| 3 | en les cultivateurs du village se cotisèrent ... | 2 |
| 4 | en el momento de la compra la tarjeta se entre... | 1 |
| 5 | le nombre de clubs engagés étant trop faible p... | 2 |
| 6 | le désastre subi par larmée de metellus permet... | 2 |
| 7 | tama-chan es el hámster mascota de anna sariza... | 1 |
| 8 | ces arbres se plaisent plutôt dans des sols fr... | 0 |
| 9 | o último encontro entre ambas equipes foi em ... | 3 |
| 10 | в январе года в прощальном матче аднана аль-т... | 0 |
| 11 | e portugal finalmente conquistou sua primeira ... | 3 |
| 12 | drača em cirílico драча é uma vila da sérvia l... | 3 |
| 13 | na série drop dead diva april interpreta a mel... | 3 |
| 14 | si f m → n est un difféomorphisme local alors... | 2 |
| 15 | labécédaire de la république et du citoyen par... | 2 |
| 16 | el portador de la bandera en la ceremonia de a... | 1 |
| 17 | в году в санкт-петербурге вышло второе издани... | 0 |
| 18 | los individuos eligen entonces los padres o tu... | 1 |
| 19 | важной стороной ломоносовской методологии явил... | 0 |
| 20 | второе направление призвано сначала привлечь м... | 0 |
| 21 | de modo geral para determinar a pressão de inj... | 3 |
| 22 | термин «онтология» был предложен рудольфом гок... | 0 |
| 23 | la homeostasis del griego ὅμοιος [homoios] «ig... | 1 |
| 24 | tipo de material – material com viscosidade ma... | 3 |
| 25 | a história da suíça propriamente dita começa a... | 3 |
| 26 | l’eurovelo ev également dénommée « la route ... | 2 |
| 27 | tibur era uma das maiores cidades latinas mas ... | 3 |
| 28 | a extinção da dinastia kyburg abriu caminho pa... | 3 |
| 29 | dans le département des landes le ruisseau de ... | 2 |
| ... | ... | ... |
| 970 | após sua vitória sobre jorge masvidal daley as... | 3 |
| 971 | la démarche ne peut aboutir sans quau préalabl... | 2 |
| 972 | расположена в юго-западной части области в км... | 0 |
| 973 | les supporters de lasm clermont auvergne ont r... | 2 |
| 974 | é um mito popular na universidade da califórni... | 3 |
| 975 | марта года вошёл в тренерский штаб цска став... | 0 |
| 976 | en sorolla y benlliure son declarados hijos p... | 1 |
| 977 | евразийская экономическая комиссия еэк — посто... | 0 |
| 978 | a heráldica refere-se simultaneamente à ciênci... | 3 |
| 979 | florimont est une commune française située dan... | 2 |
| 980 | выпуск нелицензированных копий установок «бофо... | 0 |
| 981 | lugar de realengo de españa provincia y azobis... | 3 |
| 982 | wilson d e reeder d m eds mammal species of t... | 0 |
| 983 | novidades como o corps de logis que toma uma g... | 3 |
| 984 | según el censo de [] había personas residien... | 1 |
| 985 | la mayor parte de su obra está redactada en la... | 1 |
| 986 | "pilot" é o primeiro episódio da série de tele... | 3 |
| 987 | apertura del camino real rn ahora la avenue ... | 1 |
| 988 | em de junho apenas uma semana após ser libera... | 3 |
| 989 | в - учился в школе в центре москвы закончил ... | 0 |
| 990 | tendo descrito a vitória de camilo contra os v... | 3 |
| 991 | "una acción contrarrevolucionaria es cualquier... | 1 |
| 992 | la composición fue anotada en el catálogo pers... | 1 |
| 993 | el investigador ha recibido varios reconocimie... | 1 |
| 994 | pueden funcionar como complemento directo unid... | 0 |
| 995 | el departamento cuenta con varios canales de t... | 1 |
| 996 | farrington d p b implications of biological fi... | 0 |
| 997 | клевцов в герой несуществующей державы в клев... | 0 |
| 998 | le mars tag heuer annonce à l’occasion du ba... | 2 |
| 999 | gillison douglas australia in the war of – se... | 0 |
1000 rows × 2 columns
nbrs = NearestNeighbors(n_neighbors=3, metric='euclidean').fit(tfidf_matrix.values)
clust_cnt = data['cluster'].value_counts()
clust_cnt_pct = data['cluster'].value_counts(normalize=True)
centroids = model.cluster_centers_
terms = tfidf_vect.get_feature_names()
order_centroids = centroids.argsort()[:, ::-1]
for i in range(k):
print(f"Cluster # {i}")
print(f"Tiene {clust_cnt[i]} registros ({clust_cnt_pct[i]:.2%} de los datos)")
print()
print("TÉRMINOS MÁS REPRESENTATIVOS")
for ind in order_centroids[i][:20]:
print(terms[ind], end=" ")
print()
print()
print(f"DOCUMENTOS MÁS REPRESENTATIVOS")
for vecino in data.iloc[nbrs.kneighbors([centroides[i]])[1][0]].Text.values:
print(f" *** {vecino}")
print()
print()
print("********************************************")
print()
Cluster # 0 Tiene 282 registros (28.20% de los datos) TÉRMINOS MÁS REPRESENTATIVOS на года по году для не из был от его что за церкви также ломоносова ломоносов комиссии как он the DOCUMENTOS MÁS REPRESENTATIVOS *** в году овчинников окончательно вытеснил из основы «локомотива» хасанби биджиева пропустив всего мяч в матчах и как следствие получил приглашение в только что образованную сборную россии на её первый в истории матч на стадионе «локомотив» против сборной мексики однако на поле так и не вышел на последующие матчи сборной в течение года овчинников также вызывался но оставался на скамейке запасных *** с октября года начала действия договора по апрель года товарооборот между странами увеличился на экспорт вырос на импорт — на *** в апреле года ломоносов за дерзкое поведение при академических распрях между «русской» и «немецкой» партиями был заключён под стражу на месяцев только января года сенат заслушав доклад следственной комиссии постановил «оного адъюнкта ломоносова для его довольного обучения от наказания освободить а во объявленных им продерзостях у профессоров просить прощения» и жалованье ему в течение года выдавать «половинное» в это время из германии приезжает жена елизавета следует отметить что борьба немецкой и антинемецкой партии в академии происходила на фоне конца правления анны иоановны которое характеризовалось бироновщиной и «засильем немцев» — доминированием иностранцев в государственном аппарате науке и образовании ******************************************** Cluster # 1 Tiene 251 registros (25.10% de los datos) TÉRMINOS MÁS REPRESENTATIVOS de el la en del los su que es una con se por un las al para fue como más DOCUMENTOS MÁS REPRESENTATIVOS *** cresta del club se deriva de la de los municipio de sutton la diferencia es que unidos seleccionado sólo las partes de la cresta que representan el sutton y cheam en oposición a las partes de cresta del municipio que significa beddington wallington y carshalton los discos de oro y de plata en el escudo son de los brazos del viejo burgo de sutton y cheam las llaves dentro de los discos de simbolizar la propiedad de sutton por el chertsey abbey según consta en el domesday book que se encuentra en la parte superior de la placa es de los brazos de los lumleys antiguos señores de la mansión de cheam las cruces ahora de oro en el escudo del club pero el negro en el escudo de la ciudad de representan el sede de canterbury que celebró cheam en el momento de la canuto el grande la placa también cuenta con un casco medieval *** reclutado en el verano de comenzó su carrera en el equipo de bachillerato de la universidad popular autónoma del estado de puebla upaep para después de años ingresar en la misma institución a la carrera de ciencias de la comunicación upaep es una universidad mexicana con un equipo de baloncesto de gran prestigio y tradición que ha sido campeón nacional en ocasiones durante esta temprana etapa de su carrera fue que adquirió su primer famoso apodo del grandul debido a sus metros de estatura pese a ello se coronó con un bicampeonato nacional de conadeip y una copa universitaria telcel y formar parte del cuadro ideal de conadeip en el y en fue subcampeón en el estatal de primera fuerza varonil en chiapas jugando para villaflores y realizó una gira en cuatro sedes del mismo estado reforzando a una selección estatal para medirse al hope college a partir de esto decidió emigrar a la universidad de san jose state en california us su paso por esta institución no llegó a un semestre debido a su pocas aptitudes para el estudio y el aprendizaje del idioma inglés por lo decidió retornar a su país para formar parte del equipo profesional halcones de xalapa veracruz y conseguir con ellos dos campeonatos de la lnbp y en ese país así mismo durante la etapa *** en septiembre consigue su mejor victoria como profesional en la vuelta a españa al ganar en la mítica cima del angliru tras meterse en la fuga buena del día de corredores y en los que había ciclistas de la talla de paolo tiralongo serge pauwels o david arroyo elissonde lanzó un ataque en el alto del cordal a falta de km a la meta que solo pudo ser respondido por el italiano tiralongo con el que comenzó la subida al angliru en solitario sin embargo en las primeras rampas duras del puerto soltó al transalpino y supo mantener una ventaja con el grupo de los favoritos lo que le permitió llevarse una inolvidable victoria y acabar º en la general esa victoria le encumbró como una de las jóvenes revelaciones del ciclismo francés y del mundo anteriormente en la vuelta en la º etapa con final en collada de la gallina se le dio por abandonado pero consiguió llegar a meta en última posición a más de media hora y tiritando de frío y bastante mojado tras una caótica etapa de perros ******************************************** Cluster # 2 Tiene 227 registros (22.70% de los datos) TÉRMINOS MÁS REPRESENTATIVOS de le et la les du des en est dans une par au il un avec pour qui france sur DOCUMENTOS MÁS REPRESENTATIVOS *** le rugby est en france le deuxième sport collectif le plus populaire même si dans certaines régions il fait jeu égal avec le football les régions du sud-ouest sont celles où ce sport est le plus pratiqué et suivi tandis quau nord de lhexagone il est beaucoup moins populaire hormis en île-de-france il ny a aucun club de la moitié nord de la france ayant un statut professionnel en depuis larrivée du professionnalisme dans le monde du rugby - la majorité des nations majeures dans ce sport ont choisi de regrouper les clubs en provinces franchisées en france les clubs sont très populaires et font partie du patrimoine culturel la france est aujourdhui la seule nation avec langleterre à avoir gardé son système de promotionrelégation dans le championnat délite voici le palmarès du championnat de france recensé par région *** le rugby se développe particulièrement en aquitaine sous linfluence des échanges commerciaux avec langleterre friande des vins de bordeaux les négociants en vin britanniques formant dans cette région une colonie vinicole et rugbystique le rugby sy diffuse par la suite par larrivée détudiants et de fonctionnaires de la région parisienne par linfluence de philippe tissié - promoteur du rugby dans léducation scolaire de la ligue girondine déducation physique son enracinement dans le sud-ouest sexplique aussi grâce aux stations climatiques et sportives pau biarritz où les aristocrates anglais font des cures hivernales les clubs de province sont autorisés à disputer le titre en le championnat se joue alors entre le champion de paris et celui des départements le stade bordelais sbuc en profite aussitôt pour remporter son premier titre en le sbuc gagne la finale à la régulière sur le score de à mais lusfsa annule le résultat et décide que la finale doit être rejouée à paris le stade bordelais ayant en effet fait jouer trois joueurs irrégulièrement le sbuc refusant cette décision le stade français est déclaré vainqueur *** dans ce contexte de guerre ethnique et précisément au moment où lagitation en faveur de louis riel samplifie ces nominations ne sont pas très heureuses quand mgr taché obtient un sursis dun mois pour permettre aux avocats de louis riel de porter sa cause en appel au conseil privé des émeutes contre la vaccination et la quarantaine éclatent les et septembre la foule assiège le bureau de santé du faubourg de lest et y met le feu la foule va chahuter le montreal herald on y brise les vitres et on va menacer les maisons des médecins vaccinateurs dont celle de lex-maire hingston le chef de police est blessé cest le propriétaire du journal the gazette richard white qui demande lintervention des troupes le maire honoré beaugrand alité souffrant dasthme court à son bureau et consigne militaires dans une déclaration il invite les citoyens à ne pas sortir le soir et à ne pas gêner laction de la police ******************************************** Cluster # 3 Tiene 240 registros (24.00% de los datos) TÉRMINOS MÁS REPRESENTATIVOS de em do da uma no que um com os foi na por para se como as dos mais sua DOCUMENTOS MÁS REPRESENTATIVOS *** o râguebi foi apresentado aos francesas na cidade de le havre por mercadores ingleses em e se espalhou pelo resto do país apesar de ter sido a primeira vez introduzido no norte foi no sul no meio da população rural e pobre trabalhadora dos vinhedos que o râguebi se popularizou na frança o primeiro envolvimento de uma seleção francesa do esporte foi nas olimpíadas de em paris onde uma equipe nacional competiu a recém-formada equipe derrotou os britânicos a e os alemães a ganhando assim a medalha de ouro em a seleção francesa jogou e perdeu pela primeira vez um amistoso para a nova zelândia em paris por a o primeiro jogo contra a forte seleção inglesa foi em março de em que perdeu em casa por a *** o tufão melor formou-se de uma área de perturbações meteorológicas que persistia a cerca de km a sul do atol de kwajalein ilhas marshall começou a mostrar sinais de organização em de setembro inicialmente a perturbação estava dotada de áreas fragmentadas de convecção profunda que estavam começando a girar em torno de um centro ciclônico de baixos níveis mal definido mas em processo de consolidação no dia seguinte a perturbação continuou a se organizar com a melhora dos fluxos de saída de altos níveis auxiliados pela formação de um anticiclone de altos níveis além disso a perturbação que estava embebida num cavado de monção era favorecida pelas boas condições meteorológicas para o seu desenvolvimento como o baixo cisalhamento do vento ainda naquela noite o joint typhoon warning center jtwc órgão da marinha dos estados unidos responsável pela monitoração de ciclones tropicais emitiu um alerta de formação de ciclone tropical afct sobre o sistema com base na contínua consolidação de sua circulação ciclônica de baixos níveis e na formação de novas áreas de convecção profunda o alerta significava que a perturbação poderia se tornar um ciclone tropical significativo dentro de um período de a horas no início da madrugada utc de de setembro a agência meteorológica do jap *** eleito bispo de coutances em de setembro de legado papal na inglaterra em transferido para a sé de pavia em de outubro de legado papal dos papas nicolau v e calisto iii na germânia intervindo nas dietas de ratisbona em abril de e frankfurt em outubro de sua principal incumbência era de promover a guerra contra os turcos em de setembro de ele estava com o papa na basílica patriarcal vaticana para a cerimônia da partida da cruzada legado ante o imperador frederico iii em ele foi promovido ao cardinalato a pedido do duque de milão francesco sforza ********************************************
clusters = {0: 'Ruso',
1: "Español",
2: 'Francés',
3: 'Portugués'}
data['nombres_clusters'] = data['cluster'].apply(lambda val: clusters[val])
data.sample(2)
| Text | cluster | nombres_clusters | |
|---|---|---|---|
| 816 | гео́ргий васи́льевич за́йченко июня славянс... | 0 | Ruso |
| 208 | fundada em olinda é a mais antiga entre as ci... | 3 | Portugués |
df_centroids = pd.DataFrame(centroids)
df_centroids['cluster'] = clusters.values()
df_centroids
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ... | 20448 | 20449 | 20450 | 20451 | 20452 | 20453 | 20454 | 20455 | 20456 | cluster | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2.389265e-03 | 5.421011e-20 | 0.000000e+00 | 4.065758e-20 | 8.131516e-20 | -2.710505e-20 | -1.626303e-19 | -8.131516e-20 | 8.131516e-20 | 2.439455e-19 | ... | 7.546527e-04 | -1.084202e-19 | 1.897354e-19 | 1.897354e-19 | -1.626303e-19 | -8.131516e-20 | 2.710505e-20 | 2.168404e-19 | 2.168404e-19 | Ruso |
| 1 | -9.757820e-19 | 4.065758e-20 | -2.710505e-20 | 3.411909e-04 | 8.131516e-20 | -2.710505e-20 | 4.947761e-04 | -9.486769e-20 | 3.262654e-04 | 7.837156e-04 | ... | 2.168404e-19 | 4.993962e-04 | 1.626303e-19 | 1.626303e-19 | -1.355253e-19 | -8.131516e-20 | 8.868720e-04 | 5.043687e-04 | 5.043687e-04 | Español |
| 2 | 5.709472e-04 | 1.355253e-20 | -5.421011e-20 | 2.710505e-20 | 6.776264e-20 | 9.099553e-04 | -1.626303e-19 | -9.486769e-20 | 1.355253e-20 | 2.439455e-19 | ... | 1.355253e-19 | 0.000000e+00 | 7.900961e-04 | 7.900961e-04 | 6.513262e-04 | -8.131516e-20 | 0.000000e+00 | 1.626303e-19 | 1.626303e-19 | Francés |
| 3 | -7.589415e-19 | 4.015270e-04 | 2.555090e-04 | 4.065758e-20 | 2.729548e-04 | -5.421011e-20 | -1.626303e-19 | 4.454947e-04 | 4.065758e-20 | 2.439455e-19 | ... | 1.897354e-19 | -2.710505e-20 | 1.626303e-19 | 1.626303e-19 | -1.355253e-19 | 5.559149e-04 | 0.000000e+00 | 1.897354e-19 | 1.897354e-19 | Portugués |
4 rows × 20458 columns
# ! pip install plotly
from sklearn.decomposition import PCA
import plotly.graph_objs as go
from plotly.offline import iplot
pca = PCA(n_components=2)
result = pca.fit_transform(tfidf_matrix)
result = pd.DataFrame(result)
result.columns = ['X', 'Y']
result['cluster'] = data.nombres_clusters.values
result['texto'] = data.Text.apply(lambda val: val[:140])
colorsIdx = {'Ruso': 'blue',
'Español': 'yellow',
'Portugués': 'green',
'Francés': 'red'}
result['colores'] = result['cluster'].map(colorsIdx)
result.head()
| X | Y | cluster | texto | colores | |
|---|---|---|---|---|---|
| 0 | -0.091921 | -0.062549 | Portugués | a cada etapa do circuito brasileiro banco do b... | green |
| 1 | -0.129491 | 0.015921 | Ruso | мини-бар — небольшой холодильник с напитками п... | blue |
| 2 | -0.135561 | 0.016843 | Ruso | ломоносов м в «письмо и и шувалову от года» ... | blue |
| 3 | 0.104762 | 0.212234 | Francés | en les cultivateurs du village se cotisèrent ... | red |
| 4 | 0.193633 | -0.095641 | Español | en el momento de la compra la tarjeta se entre... | yellow |
trace = go.Scatter(x=result['X'].values,
y=result['Y'].values,
text=result['texto'].values,
mode='markers',
marker=dict(color=result['colores'].values))
layout = go.Layout(title="PCA")
fig = go.Figure(data=trace, layout=layout)
iplot(fig)
Paso 3: Hacer predicciones
nuevo = ["El vecino de la profesora puso música esta tarde",
"Bom dia pessoal, o Brasil é o melhor pais do mundo",
"La serie Game of Thrones ganó en los TV Awards of Los Angeles",
"Bom dia meus caros amigos, buenos días mis queridos amigos"]
nuevo_trans = tfidf_vect.transform(nuevo)
[clusters[i] for i in model.predict(nuevo_trans)]
['Español', 'Portugués', 'Español', 'Ruso']
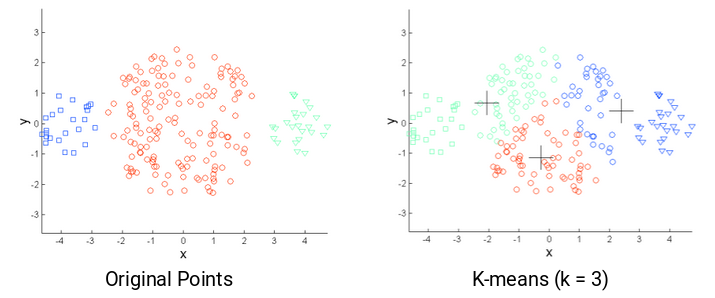
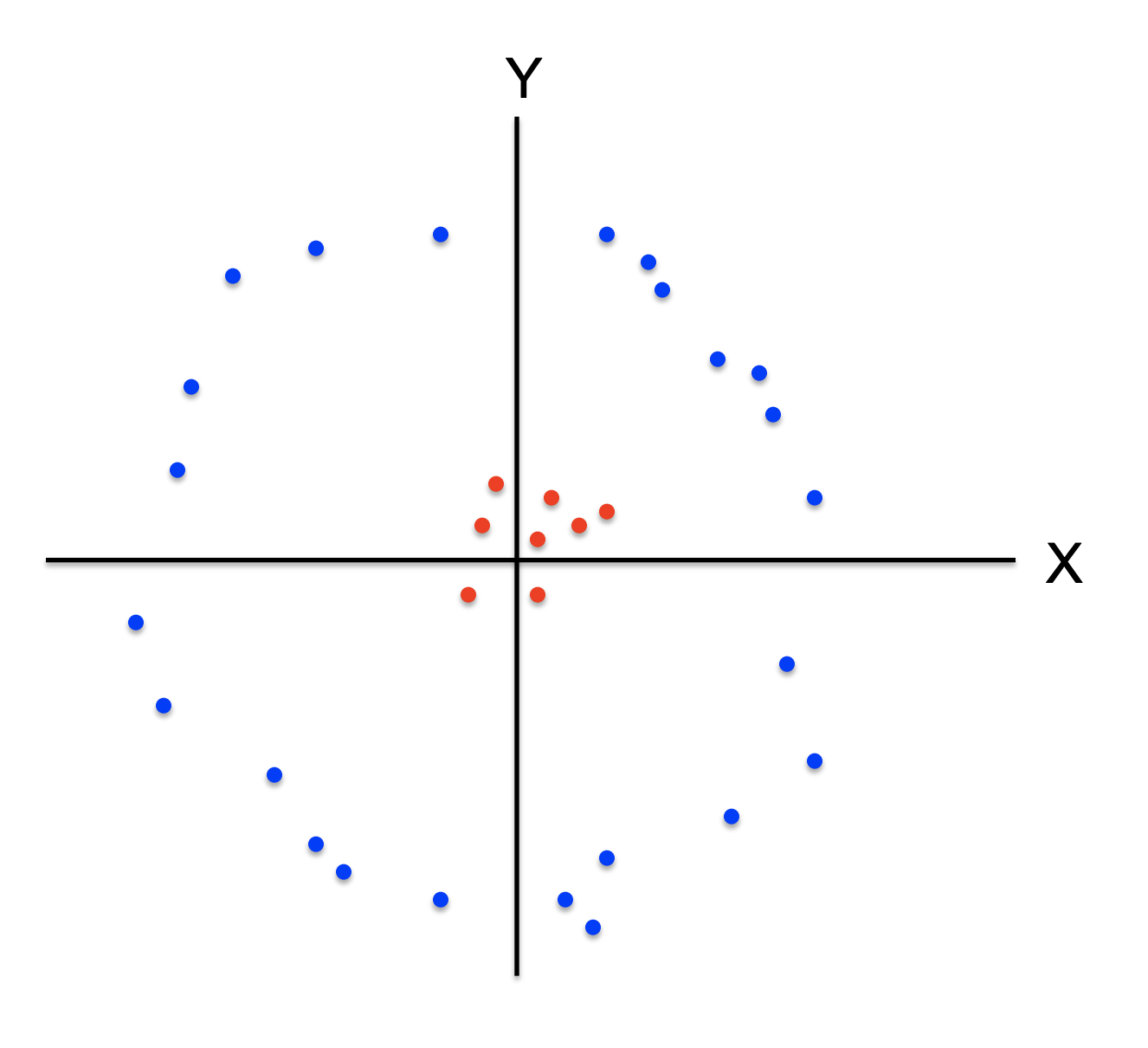
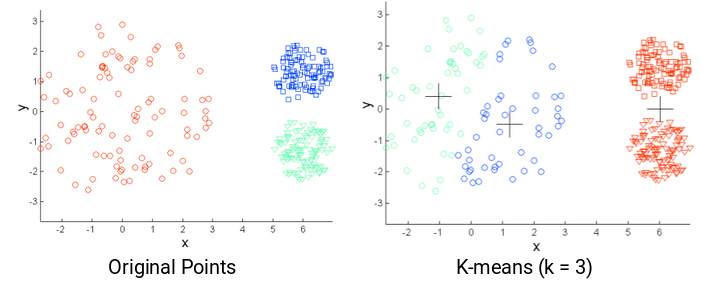
Desventajas de K-means
• Se tiene que escoger $K$ con antelación (más de eso adelante)
• Es intensivo computacionalmente
• Cada observación pertenece a un sólo cúmulo
• Sensible a las observaciones atípicas
• No puede modelar relaciones complejas
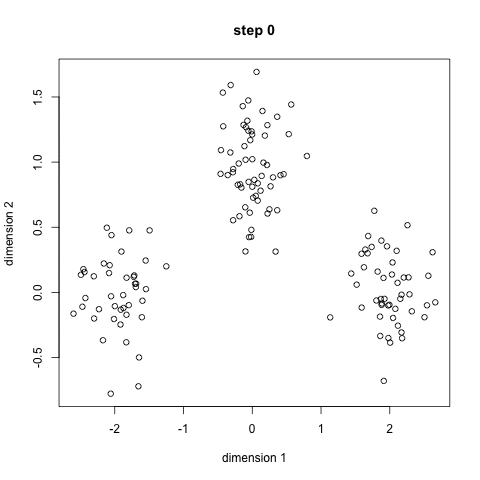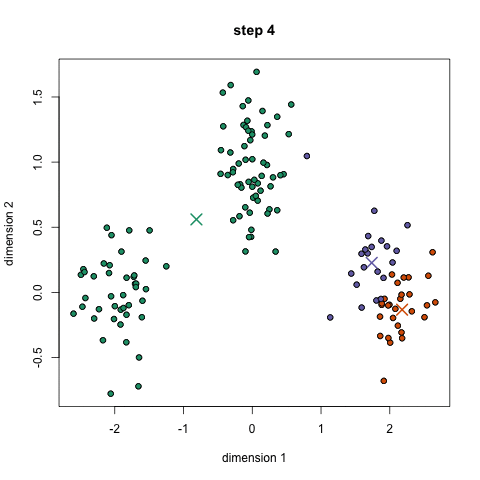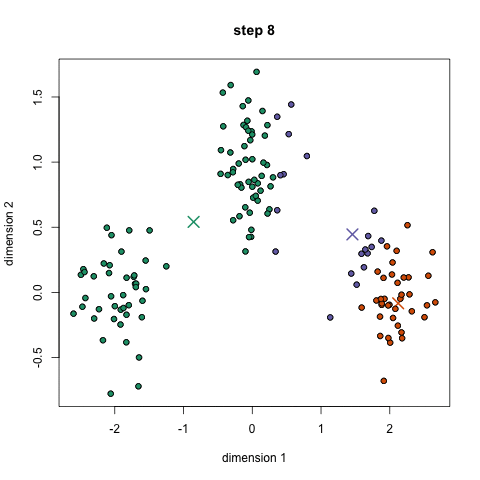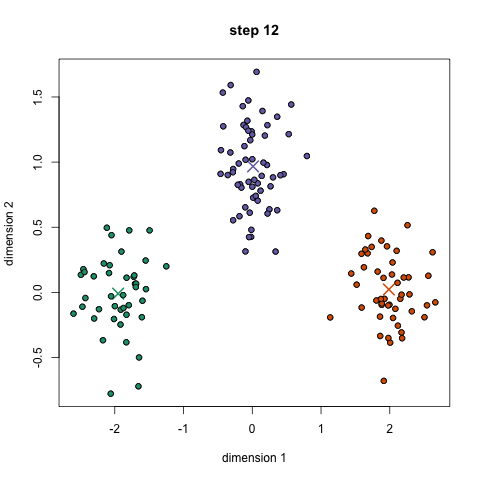
• Los modelos de agrupación son técnicas no supervisadas de Machine Learning que buscan extraer la estructura de los datos al juntar las observaciones similares.
• K-means es el modelo de agrupación más usado
• El algoritmo es iterativo y reasigna los centroides hasta cuando ya no haya cambio en los grupos
• Como todo modelo, es importante hacer una buena selección de variables dependientes y usar conocimento del tema para evaluar e interpretar el modelo.
• Hay que considerar las limitaciones del modelo a la hora de escoger trabajar o no con él.

Taller #8: K-Means
Fecha de entrega: Abril 29, 2021. (Antes del inicio de la próxima clase)