📊 Logistic Regression in Python¶
Viviana Márquez
http://vivianamarquez.com
✅ Today's Goals:¶
• Learn what Logistic Regression is.
• When should you use Logistic Regression.
• Build a machine learning model on a real-world application in Python.


🥊 Linear Regression vs Logistic Regression¶
• Linear regression is used to predict/forecast values (continuous values)
• Logistic regression is used classification tasks (discrete values: yes/no, dead/alive, pass/fail, ham/spam)
[Recap] Linear Regression¶
where $y$ is the dependent variable and $x_1,x_2,...,x_n$ are the explanatory variables.
• In Linear Regression, the predicted value can be anywhere between $-\infty$ to $\infty$.
• For Logistic Regression, we need the values to be between 0 and 1.
Our friend: The Sigmoid Function¶
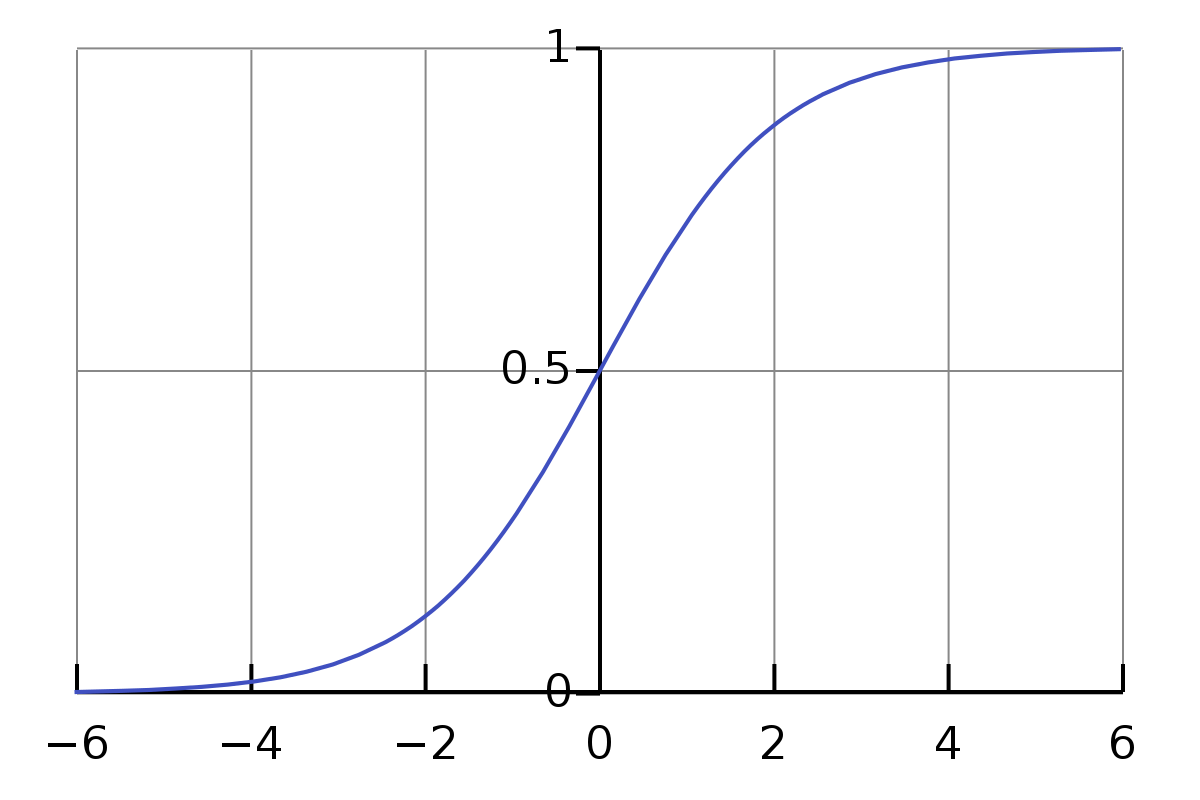 $y = \dfrac{1}{1+e^{-x}}$
$y = \dfrac{1}{1+e^{-x}}$
• Applying the Sigmoid function on linear regression, we obtain logistic regression:


import pandas as pd
# Load data
data = pd.read_csv("Pokemon.csv")
# Clean data
filter_pokemon = ["Water", "Fire"]
data = data[data['Type 1'].isin(filter_pokemon)]
data = data.reset_index()
data = data.drop(['Type 2', 'Total','Generation','Legendary', "#", "index"], axis=1)
# Preview data
data.head()
X = data[data.columns[2:]]
y = data['Type 1']
X.head()
y.head()
# Split data
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
🛂 What is the shape of X_train, X_test, y_train, y_test?
print(X.shape)
print(X_train.shape)
print(X_test.shape)
print(y.shape)
print(y_train.shape)
print(y_test.shape)
# Model
from sklearn.linear_model import LogisticRegression
logreg = LogisticRegression()
logreg.fit(X_train,y_train)
y_pred = logreg.predict(X_test)
Is our model working?¶
from sklearn import metrics
metrics.accuracy_score(y_test, y_pred)

Charmeleon
data[data['Name']=="Charmeleon"][data.columns[2:]]
# Predict Charmeleon
logreg.predict(data[data['Name']=="Charmeleon"][data.columns[2:]])

Wartortle
# Predict Wartortle
logreg.predict(data[data['Name']=="Wartortle"][data.columns[2:]])
How to improve our model?¶
from sklearn import metrics
cnf_matrix = metrics.confusion_matrix(y_test, y_pred)
cnf_matrix
data['Type 1'].value_counts()